《Elasticsearch技术解析与实战》Chapter 2.1 Elasticsearch索引增删改查
1. 创建索引
1 | PUT /lujiahao123 |
1 | PUT /lujiahao123 |
1 | <!-- Spring Boot Elasticsearch 依赖 --> |
1 |
|
1 |
|
1 |
|
1 | (SpringRunner.class) |
1 | <!--elasticsearch--> |
同上
1 |
|
1 | (SpringRunner.class) |
1 | https://github.com/lujiahao0708/LearnSeries/tree/master/LearnElasticSerach |
本文同步发表在公众号,欢迎大家关注!😁
后续笔记欢迎关注获取第一时间更新!
语法格式:
PUT /index/type/id
{
"json数据"
}输入:
PUT /person/chinese/1
{
"id":12345,
"name":"lujiahao",
"age":18
}输出:
{
"_index": "person",
"_type": "chinese",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}es会自动建立index和type,不需要提前创建,而且es默认会对document每个field都建立倒排索引,让其可以被搜索。
格式:
GET /index/type/id输入:
GET /person/chinese/1输出:
{
"_index": "person",
"_type": "chinese",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"id": 12345,
"name": "lujiahao",
"age": 18
}
}格式:
PUT /index/type/id
{
"json数据"
}输入:
PUT /person/chinese/1
{
"name":"lujiahao123"
}输出:
{
"_index": "person",
"_type": "chinese",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}查询:
{
"_index": "person",
"_type": "chinese",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"name": "lujiahao123"
}
}替换方式更新文档时,必须带上所有的field,才能去进行信息的修改;如果缺少field就会丢失部分数据。其原理时替换,因此需要全部字段。不推荐此种方式更新文档。
格式:
POST /index/type/id/_update
{
"doc":{
"json数据"
}
}输入:
POST /person/chinese/1/_update
{
"doc":{
"name":"lujiahao10010"
}
}输出:
{
"_index": "person",
"_type": "chinese",
"_id": "1",
"_version": 4,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}再次查询:
{
"_index": "person",
"_type": "chinese",
"_id": "1",
"_version": 6,
"found": true,
"_source": {
"id": 12345,
"name": "lujiahao10010",
"age": 18
}
}格式:
DELETE /index/type/id/_update
{
"doc":{
"json数据"
}
}输入:
DELETE /person/chinese/1输出:
{
"found": true,
"_index": "person",
"_type": "chinese",
"_id": "1",
"_version": 7,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}再次查询:
{
"_index": "person",
"_type": "chinese",
"_id": "1",
"found": false
}本文所有操作都是在kibana的Dev tools中进行的,相较于Elasticsearch-Heade插件,kibana中更加方便与美观(个人观点),推荐大家使用。
本文同步发表在公众号,欢迎大家关注!😁
后续笔记欢迎关注获取第一时间更新!
1 | https://www.elastic.co/downloads/elasticsearch |
1 | tar -zxvf elasticsearch-6.7.0.tar.gz |
1 | cd elasticsearch-6.7.0 |
1 | curl http://localhost:9200 或者浏览器访问 |
官方文档 : https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html
1 | docker pull docker.elastic.co/elasticsearch/elasticsearch:5.5.1 |
1 | docker run -p 9200:9200 9300:9300 -e "http.host=0.0.0.0" -e “transport.host=0.0.0.0" --name elasticsearch_5.5.0 -d docker.elastic.co/elasticsearch/elasticsearch:5.5.0 |
1 | 进入到容器中 : docker exec -it elasticsearch_5.5.0 /bin/bash |
1 | http://服务器ip:9200 |
本文同步发表在公众号,欢迎大家关注!😁
后续笔记欢迎关注获取第一时间更新!
Elasticsearch是一个机遇Lucene构建的开源、分布式、RESTful接口全文搜索引擎。同时,Elasticsearch还是一个分布式文档数据库,能够扩展至数百个服务器存储以处理PB级数据,通常作为复杂搜索场景的首选利器。
Elasticsearch的优点:
Elasticsearch wiki:https://zh.wikipedia.org/wiki/Elasticsearch
在数据量少的情况下可以当做搜索服务来使用,然而数据库归根结底是做持久化存储。如果数据量大就需要做搜索服务,底层数据还是关系数据库。我司老系统中有一个订单表,数据量已经高达两亿,客服等后台系统通常带有范围或批量条件等查询,这时数据库基本上就无法响应了,报警根本停不下来。因此,用数据库来实现搜索,性能差,可用性不高。
Lucene是一个开源的全文搜索引擎工具包,其目的是为开发者提供一个简单工具包,以快速实现全文检索的功能。
Lucene wiki:https://zh.wikipedia.org/wiki/Lucene
倒排索引中的索引对象是文档或者文档集合中的单词等,用来存储这些单词在一个文档或者一组文档中的存储位置,是对文档或者文档集合的一种最常用的索引机制。搜索引擎的关键步骤就是建立倒排索引,下面介绍Lucene是如何建立倒排索引和相应的生成算法。
假设有两篇文章:
文章1:Tom lives in Guangzhou, I live in Guangzhou too.
文章2:He once lived in Shanghai.
Lucene是基于关键词索引和查询的,首先要进行关键词提取:
分词:英文单词由空格分隔,较好处理;中文词语由于是连在一起的,需要进行特殊的分词处理(后面会介绍分词器相关知识)。
过滤无概念词语:英文中“in”“once”“too”等词没有实际意义;中文中“的”“是”等也无实际意义,这些无概念词语可以过滤掉。
统一大小写:“he”和“HE”表示的含义一样,所以单词需要统一大小写。
语义还原:通常用户查询“live”时希望能将“lives”和“lived”也查询出来,所以需要将“lives”和“lived”还原成“live”。
过滤标点符号
经过以上过滤,得到如下结果:
文章1关键词:tom live guangzhou i live guangzhou
文章2关键词:he live shanghai
关键词建立完成后,就可以进行倒排索引建立了。过滤后的关系是:“文章号“对”文章中所有关键词“,倒排索引把这个关系倒过来变成:”关键词“对”拥有关键词的所有文章号“。
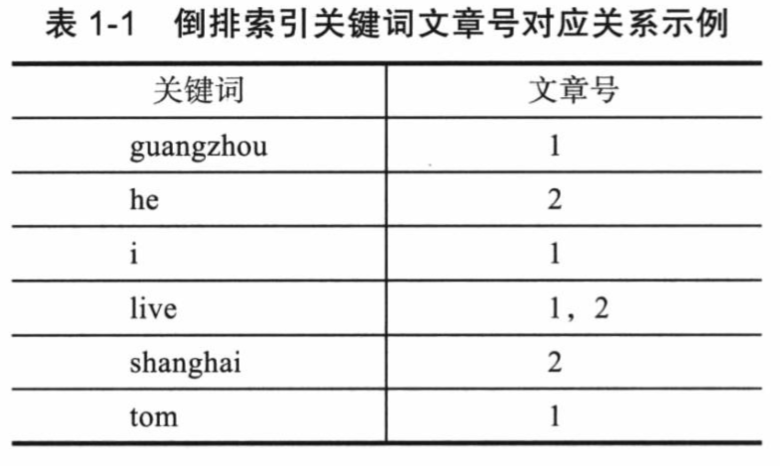
通常仅知道关键词在哪些文章中出现还不够,还需要知道关键词在文章中出现的次数和位置,通常有两种位置:
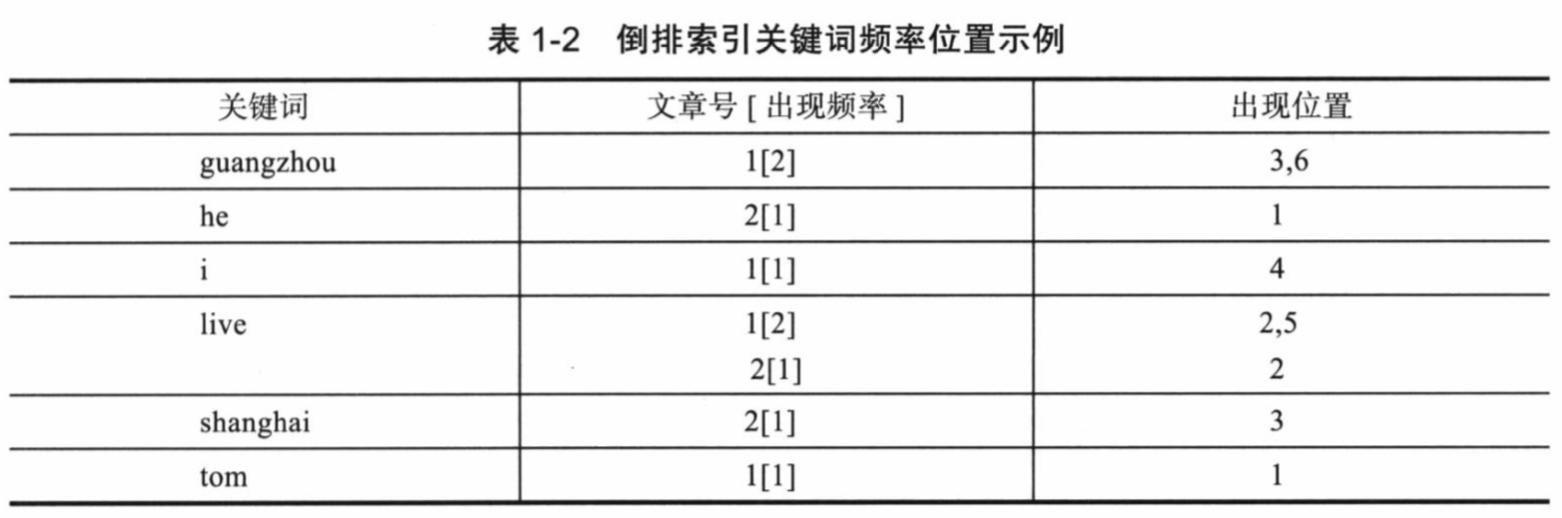
以上就是Lucene索引结构中最核心的部分,关键字是按字符顺序排列的(Lucene没有使用B树结构),因此Lucene可以使用二元搜索算法快速定位关键词。
Lucene将上面三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)、位置文件(positions)保存。其中词典文件不仅保存了每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息。
Lucene中使用了field的概念,用于表达信息所在的位置(如标题中、文章中、url中),在建索引中,该field信息也记录在词典文件中,每个关键词都有一个field信息,因为每个关键字一定属于一个或多个field。
为了减小索引文件的大小,Lucene对索引还是用了压缩技术。
首先,对词典文件中的关键词进行压缩,关键词压缩为<前缀长度,后缀>,例如:当前词为”阿拉伯语“,上一个词为”阿拉伯“,那么”阿拉伯语“压缩为<3,语>。
其次大量用到的是对数字的压缩,数字只保存与上一个值的差值(这样可以减少数字的长度,进而减少保存该数字需要的字节数)。例如当前文章号是16389(不压缩要用3个字节),上一文章号是16382,压缩后保存7(只用一个字节)。
压缩算法推荐阅读:https://www.cnblogs.com/dreamroute/p/8484457.html
查询单词”live“,Lucene先对词典二元查找,找到该词,通过指向频率文件的指针读出所有文章号,然后返回结果。词典通常非常小,可以达到毫秒级返回。而用普通的顺序匹配算法,不建立索引,而是对所有文章的内容进行字符串匹配,过程是很缓慢的,当数据量很大时,耗时更加严重。
Elasticsearch中能够被索引的精确值。foo、Foo、FOO几个单词是不同的索引词。索引词可以通过term查询进行准确的搜索。
文本会被拆分成一个个索引词存储在索引库中,为后续搜索提供支持。
分析是将文本转换为索引词的过程,其结果依赖于分词器。
集群由一个或多个节点组成,对外提供服务。Elasticsearch节点如果有相同的集群名称会自动加入到同一个集群,因此如果你拥有多个独立集群,每个集群都要设置不同的名称。
节点是一个逻辑上独立的服务,是集群的一部分,可以存储数据,并参与集群的索引和搜索功能。
文档存储时是通过散列值进行计算,最终选择存储在主分片中,这个值默认是由文档的ID生成。
分片是单个Lucene实例,是Elasticsearch管理的比较底层的功能。当索引占用空间很大超过一个节点的物理存储,Elasticsearch将索引切分成多个分片,分散在不同的物理节点上,以解决单物理节点存储空间有限的问题。
每个文档都存储在一个分片中,存储文档时系统会首先存储在主分片中,然后复制到不同的副本中。默认情况下一个索引拥有5个主分片,分片一旦建立,主分片数量就无法修改。
每个主分片有零个或多个副本,是主分片的复制,其主要目的是:
主分片的数据会复制到副本分片中,这样避免了单点问题,当某个节点发生故障,复制可以对故障进行转移,保证系统的高可用。
索引是具有相同结构的文档合集。
一个索引可以定义一个或多个类型,类型是索引的逻辑分区。
文档是存储在Elasticsearch中的一个JSON格式的字符串,就像关系数据库中表的一行记录。
映射像关系数据库中的表结构,每个索引都有一个映射,它定义了索引中的每一个字段类型。映射可以事先被定义,也可以在第一次存储文档时被自动识别。
文档中包含零个或多个字段,字段可以是一个简单的值,也可以是一个数组或对象的嵌套结构。字段类似于关系数据库中表的列,每个字段都对应一个字段类型。
默认情况下源文档将被存储在_source字段中,查询时返回该字段。
ID是文件的唯一标识,如果未指定,系统会自动生成一个ID,文档的index/type/id必须是唯一的。
| Elasticsearch | 数据库 |
|---|---|
| Document | row 行 |
| Type | table 表 |
| Index | database 库 |
本文同步发表在公众号,欢迎大家关注!😁
后续笔记欢迎关注获取第一时间更新!
DateFormat方法也有它自己的问题。比如,它不是线程安全的。这意味着两个线程如果尝试使用同一个formatter解析日期,你可能会得到无法预期的结果。
Java 8提供新的日期和时间API,LocalDate类实例是一个不可变对象,只提供简单的日期并且不含当天时间信息。此外也不附带任何与时区相关的信息。
通过静态工厂方法of创建一个LocalDate实例。LocalDate实例提供了多种方法来读取常用的值,比如年份、月份、星期几等,如下所示。
1 | LocalDate localDate = LocalDate.of(2014, 3, 18); |
Java 8日期-时间类都提供了类似的工厂方法。通过传递TemporalField参数给get方法拿到同样的信息。TemporalField接口定义了如何访问temporal对象某个字段的值。ChronoField枚举实现TemporalField接口,可以使用get方法得到枚举元素的值。
1 | int year = localDate.get(ChronoField.YEAR); |
使用LocalTime类表示时间,可以使用of重载的两个工厂方法创建LocalTime的实例。
LocalTime类也提供了一些get方法访问这些变量的值,如下所示。
1 | LocalTime localTime = LocalTime.of(13, 45, 20); |
LocalDate和LocalTime都可以通过解析代表它们的字符串创建。使用静态方法parse可以实现:
1 | LocalDate date = LocalDate.parse("2019-03-27"); |
可以向parse方法传递一个DateTimeFormatter。该类的实例定义了如何格式化一个日期或者时间对象。用来替换老版java.util.DateFormat。
如果传递的字符串参数无法被解析为合法的LocalDate或LocalTime对象,这两个parse方法都会抛出一个继承自RuntimeException的DateTimeParseException异常。
复合类LocalDateTime,是LocalDate和LocalTime的合体。它同时表示了日期和时间,不带有时区信息。可以直接创建,也可以通过合并日期和时间对象构造。
1 | LocalTime time = LocalTime.of(21, 31, 50); |
创建LocalDateTime对象
也可以使用toLocalDate或者toLocalTime方法,从LocalDateTime中提取LocalDate或者LocalTime组件:
1 | LocalDate date1 = dt1.toLocalDate(); |
从计算机的角度来看,”2019年03月27日11:20:03”这样的方式是不容易理解的,计算机更加容易理解建模时间最自然的格式是表示一个持续时间段上某个点的单一大整型数。新的java.time.Instant类对时间建模的方式,基本上它是以Unix元年时间(传统的设定为UTC时区1970年1月1日午夜时分)开始所经历的秒数进行计算。
1 | Instant.ofEpochSecond(3); |
Instant类也支持静态工厂方法now,它能够获取当前时刻的时间戳。
1 | Instant now = Instant.now(); |
Instant的设计初衷是为了便于机器使用,它包含的是由秒及纳秒所构成的数字。因此Instant无法处理那些我们非常容易理解的时间单位。
1 | int day = Instant.now().get(ChronoField.DAY_OF_MONTH); |
所有类都实现了Temporal接口,该接口定义如何读取和操纵为时间建模的对象的值。如果需要创建两个Temporal对象之间的duration,就需要Duration类的静态工厂方法between。
可以创建两个LocalTimes对象、两个LocalDateTimes对象,或者两个Instant对象之间的duration:
1 | LocalTime time1 = LocalTime.of(21, 50, 10); |
LocalDateTime是为了便于人阅读使用,Instant是为了便于机器处理,所以不能将二者混用。如果在这两类对象之间创建duration,会触发一个DateTimeException异常。
此外,由于Duration类主要用于以秒和纳秒衡量时间的长短,你不能仅向between方法传递一个LocalDate对象做参数。
使用Period类以年、月或者日的方式对多个时间单位建模。使用该类的工厂方法between,可以使用得到两个LocalDate之间的时长。
1 | Period period = Period.between(LocalDate.of(2019, 03, 7), LocalDate.of(2019, 03, 17)); |
Duration和Period类都提供了很多非常方便的工厂类,直接创建对应的实例。
1 | Duration threeMinutes = Duration.ofMinutes(3); |
截至目前,我们介绍的这些日期-时间对象都是不可修改的,这是为了更好地支持函数式编程,确保线程安全,保持领域模式一致性而做出的重大设计决定。
当然,新的日期和时间API也提供了一些便利的方法来创建这些对象的可变版本。比如,你可能希望在已有的LocalDate实例上增加3天。除此之外,我们还会介绍如何依据指定的模式,
比如dd/MM/yyyy,创建日期-时间格式器,以及如何使用这种格式器解析和输出日期。
如果已经有一个LocalDate对象,想要创建它的一个修改版,最直接也最简单的方法是使用withAttribute方法。withAttribute方法会创建对象的一个副本,并按照需要修改它的属性。
1 | // 这段代码中所有的方法都返回一个修改了属性的对象。它们都不会修改原来的对象! |
它们都声明于Temporal接口,所有的日期和时间API类都实现这两个方法,它们定义了单点的时间,比如LocalDate、LocalTime、LocalDateTime以及Instant。更确切地说,使用get和with方法,我们可以将Temporal对象值的读取和修改区分开。如果Temporal对象不支持请求访问的字段,它会抛出一个UnsupportedTemporalTypeException异常,比如试图访问Instant对象的ChronoField.MONTH_OF_YEAR字段,或者LocalDate对象的ChronoField.NANO_OF_SECOND字段时都会抛出这样的异常。
1 | // 以声明的方式操纵LocalDate对象,可以加上或者减去一段时间 |
与我们刚才介绍的get和with方法类似最后一行使用的plus方法也是通用方法,它和minus方法都声明于Temporal接口中。通过这些方法,对TemporalUnit对象加上或者减去一个数字,我们能非常方便地将Temporal对象前溯或者回滚至某个时间段,通过ChronoUnit枚举我们可以非常方便地实现TemporalUnit接口。
有时需要进行一些更加复杂的操作,比如,将日期调整到下个周日、下个工作日,或者是本月的最后一天。可以使用重载版本的with方法,向其传递一个提供了更多定制化选择的TemporalAdjuster对象,更加灵活地处理日期。
1 | // 对于最常见的用例,日期和时间API已经提供了大量预定义的TemporalAdjuster。可以通过TemporalAdjuster类的静态工厂方法访问。 |
使用TemporalAdjuster可以进行更加复杂的日期操作,方法的名称很直观。如果没有找到符合预期的预定义的TemporalAdjuster,可以创建自定义的TemporalAdjuster。TemporalAdjuster接口只声明一个方法(即函数式接口)。实现该接口需要定义如何将一个Temporal对象转换为另一个Temporal对象,可以把它看成一个UnaryOperator
1 |
|
新的java.time.format包就是特别为格式化以及解析日期-时间对象而设计的。其中最重要的类是DateTimeFormatter。创建格式器最简单的方法是通过它的静态工厂方法以及常量。所有的DateTimeFormatter实例都能用于以一定的格式创建代表特定日期或时间的字符串。
1 | LocalDate date = LocalDate.of(2013, 10, 11); |
通过解析代表日期或时间的字符串重新创建该日期对象,也可以使用工厂方法parse重新创建。
1 | LocalDate date2 = LocalDate.parse("20141007", DateTimeFormatter.BASIC_ISO_DATE); |
DateTimeFormatter实例是线程安全的,老的java.util.DateFormat线程不安全。单例模式创建格式器实例,在多个线程间共享实例是没有问题的。也可以通过ofPattern静态工厂方法,按照某个特定的模式创建格式器。
1 | DateTimeFormatter formatter = DateTimeFormatter.ofPattern("dd/MM/yyyy"); |
ofPattern方法也提供了一个重载的版本,可以传入Locale创建格式器。
1 | DateTimeFormatter italianFormatter = DateTimeFormatter.ofPattern("d. MMMM yyyy", Locale.ITALIAN); |
DateTimeFormatterBuilder类还提供了更复杂的格式器,以提供更加细粒度的控制。同时也提供非常强大的解析功能,比如区分大小写的解析、柔性解析、填充,以及在格式器中指定可选节等等。
通过DateTimeFormatterBuilder自定义格式器
1 | DateTimeFormatter italianFormatter = new DateTimeFormatterBuilder() |
新版日期和时间API新增加的重要功能是时区的处理。新的java.time.ZoneId类替代老版java.util.TimeZone。跟其他日期和时间类一样,ZoneId类也是无法修改的。是按照一定的规则将区域划分成的标准时间相同的区间。在ZoneRules这个类中包含了40个时区实例,可以通过调用ZoneId的getRules()得到指定时区的规则,每个特定的ZoneId对象都由一个地区ID标识。
1 | ZoneId shanghaiZone = ZoneId.of("Asia/Shanghai"); |
Java 8的新方法toZoneId将一个老的时区对象转换为ZoneId。地区ID都为“{区域}/{城市}”的格式,地区集合的设定都由英特网编号分配机构(IANA)的时区数据库提供。
1 | ZoneId zoneId = TimeZone.getDefault().toZoneId(); |
ZoneId对象可以与LocalDate、LocalDateTime或者是Instant对象整合构造为成ZonedDateTime实例,它代表了相对于指定时区的时间点。
1 | LocalDate date = LocalDate.of(2019, 03, 27); |
另一种比较通用的表达时区的方式是利用当前时区和UTC/格林尼治的固定偏差。使用ZoneId的一个子类ZoneOffset,表示的是当前时间和伦敦格林尼治子午线时间的差异:
1 | ZoneOffset newYorkOffset = ZoneOffset.of("-05:00"); |
某个网站的数据来自Facebook、Twitter和Google,这就需要网站与互联网上的多个Web服务通信。可是,你并不希望因为等待某些服务的响应,阻塞应用程序的运行,浪费数十亿宝贵的CPU时钟周期。比如,不要因为等待Facebook的数据,暂停对来自Twitter的数据处理。
第7章中介绍的分支/合并框架以及并行流是实现并行处理的宝贵工具;它们将一个操作切分为多个子操作,在多个不同的核、CPU甚至是机器上并行地执行这些子操作。与此相反,如果你的意图是实现并发,而非并行,或者你的主要目标是在同一个CPU上执行几个松耦合的任务,充分利用CPU的核,让其足够忙碌,从而最大化程序的吞吐量,那么你其实真正想做的是避免因为等待远程服务的返回,或者对数据库的查询,而阻塞线程的执行,浪费宝贵的计算资源,因为这种等待的时间很可能相当长。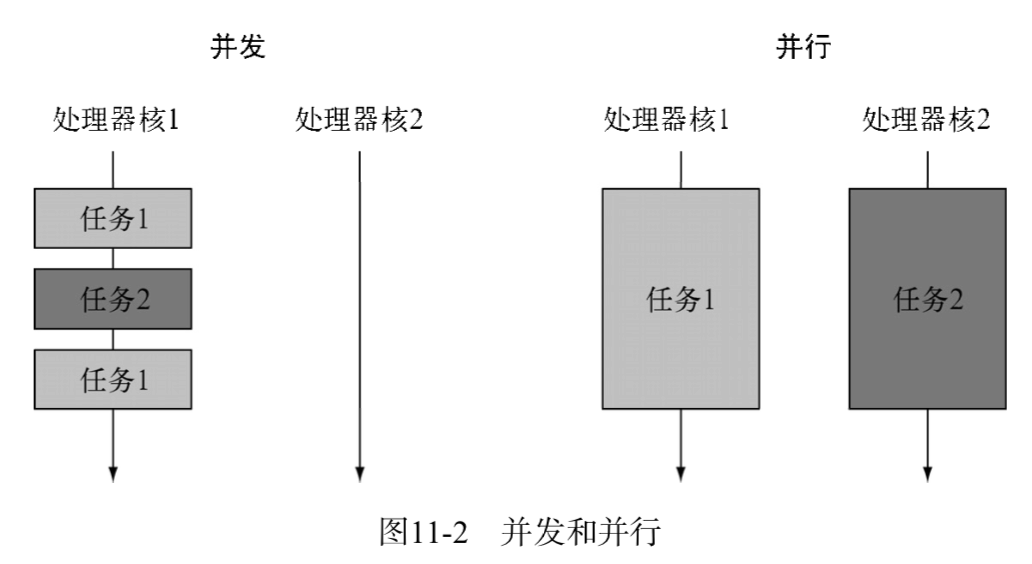
Future接口在Java 5中被引入,设计初衷是对将来某个时刻会发生的结果进行建模。它建模了一种异步计算,返回一个执行运算结果的引用,当运算结束后,这个引用被返回给调用方。在Future中触发那些潜在耗时的操作把调用线程解放出来,让它能继续执行其他有价值的工作,不再需要等待耗时的操作完成。Future的另一个优点是它比更底层的Thread更易用。要使用Future,通常你只需要将耗时的操作封装在一个Callable对象中,再将它提交给ExecutorService。使用Future以异步的方式执行一个耗时的操作: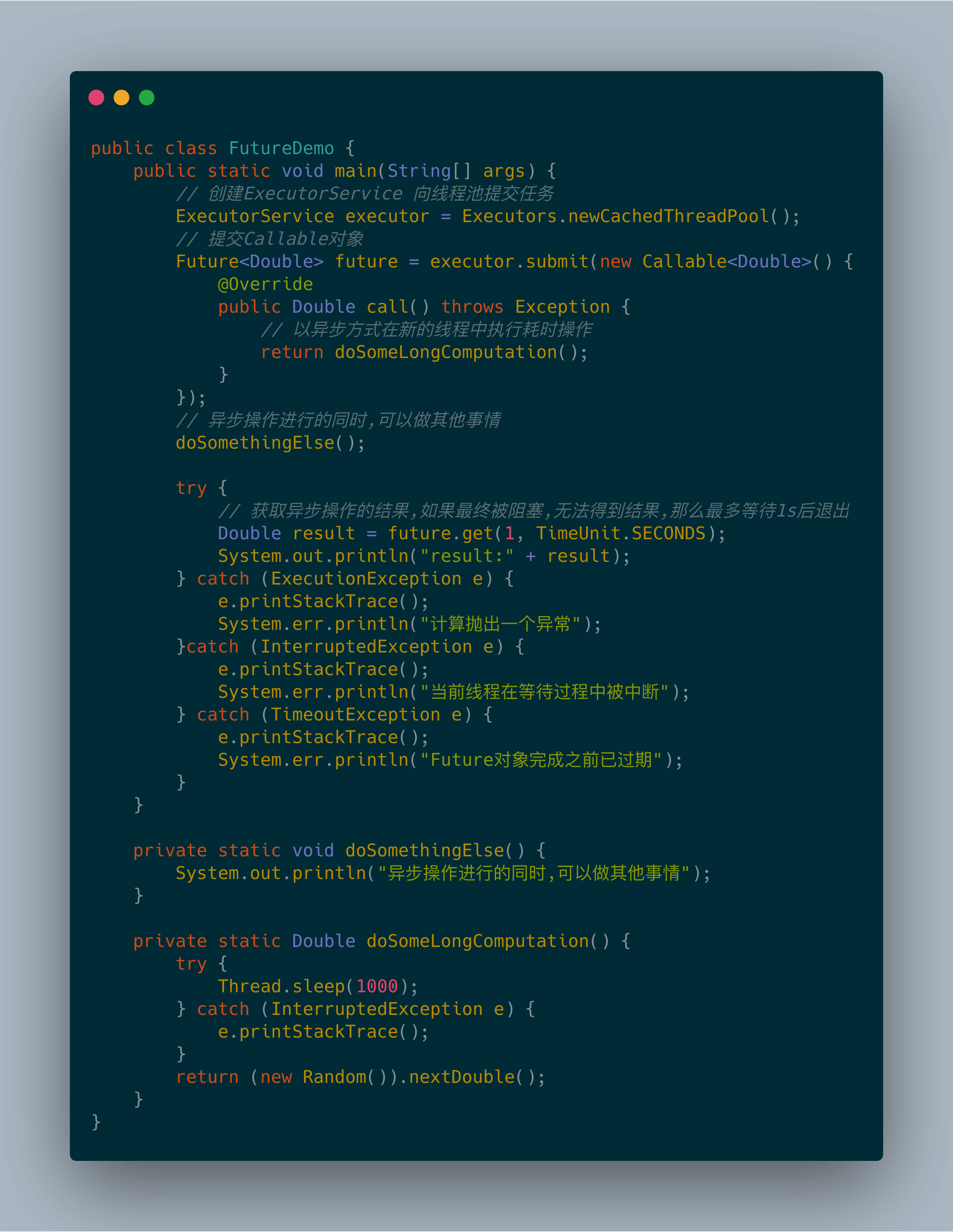
线程可以在ExecutorService以并发方式调用另一个线程执行耗时操作的同时,去执行一些其他的任务。接着,如果你已经运行到没有异步操作的结果就无法继续任何有意义的工作时,可以调用它的get方法去获取操作的结果。如果操作已经完成,该方法会立刻返回操作的结果,否则它会阻塞你的线程,直到操作完成,返回相应的结果。如果该长时间运行的操作永远不返回了会怎样?Future提供了一个无需任何参数的get方法,推荐使用重载版本的get方法,它接受一个超时的参数,可以定义线程等待Future结果的最长时间,避免无休止的等待。下图是Future异步执行线程原理图。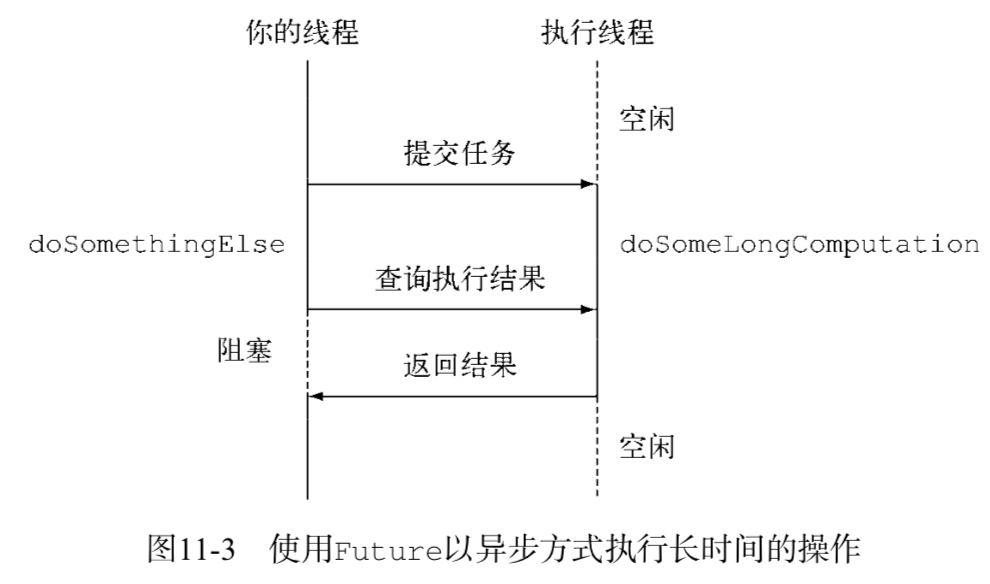
Future接口有一定的局限性,比如,我们很难表述Future结果之间的依赖性。因此我们引入了CompletableFuture。接下来通过一个“最佳价格查询器“的应用,它会查询多个在线商店,依据给定的产品或服务找出最低的价格,来展现CompletableFuture实现异步应用。通过此例你能学到这些:
同步API和异步API:

同步操作中会为等待同步事件完成而等待1s,这种是无法接受的,对于程序体验来说是非常不好的。
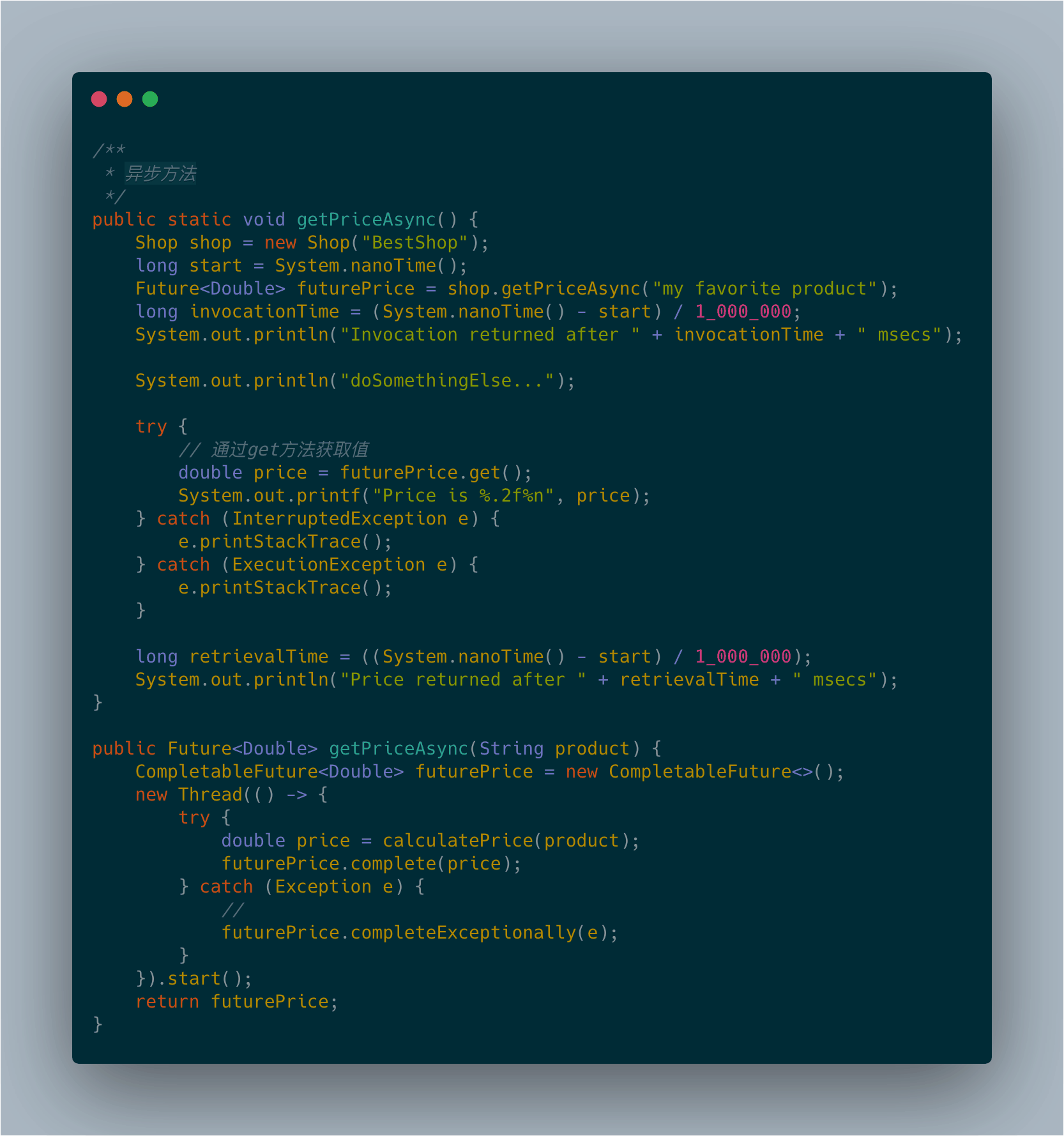
Java 5引入了java.util.concurrent.Future接口表示一个异步计算(即调用线程可以继续运行,不会因为调用方法而阻塞)的结果。这意味着Future是一个暂时还不可知值的处理器,这个值在计算完成后,可以通过调用它的get方法取得。这种方式下,在进行价格查询的同时,还能执行一些其他的任务,比如查询其他商店中商品的价格,不会阻塞在那里等待第一家商店返回请求的结果。最后,如果所有有意义的工作都已经完成,所有要执行的工作都依赖于商品价格时,再调用Future的get方法。执行了这个操作后,要么获得Future中封装的值(如果异步任务已经完成),要么发生阻塞,直到该异步任务完成,期望的值能够访问。同时,如果某个商品价格计算发生异常,会将当前线程杀死,从而导致等待get方法返回结果的客户端永久地被阻塞。客户端可以使用重载版本的get方法,设置超时参数来避免。为了让客户端能了解无法提供请求商品价格的原因,你需要使用CompletableFuture的completeExceptionally方法将导致CompletableFuture内发生问题的异常抛出。
.png)
supplyAsync方法接受一个生产者(Supplier)作为参数,返回一个CompletableFuture对象,该对象完成异步执行后会读取调用生产者方法的返回值。生产者方法会交由ForkJoinPool池中的某个执行线程(Executor)运行,但是你也可以使用supplyAsync方法的重载版本,传递第二个参数指定不同的执行线程执行生产者方法。
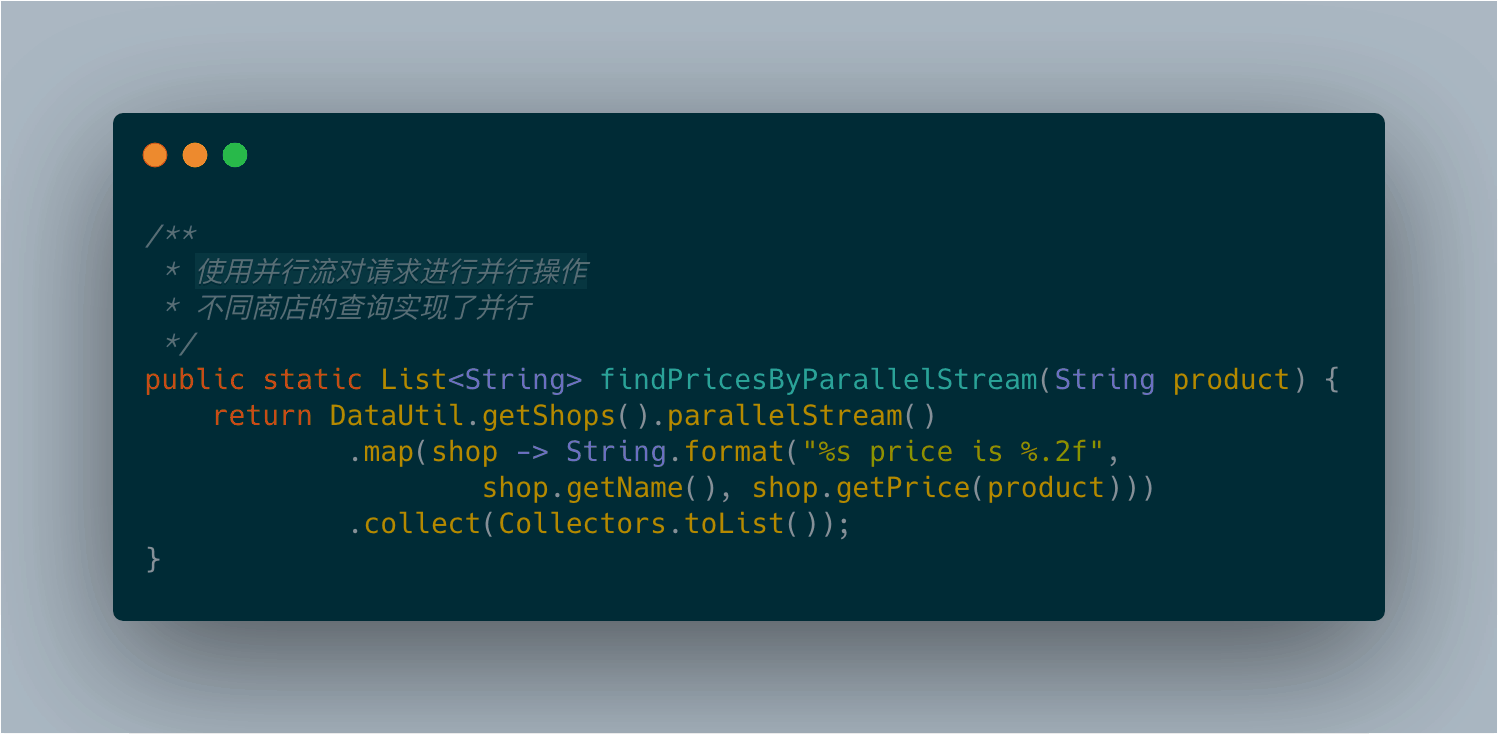

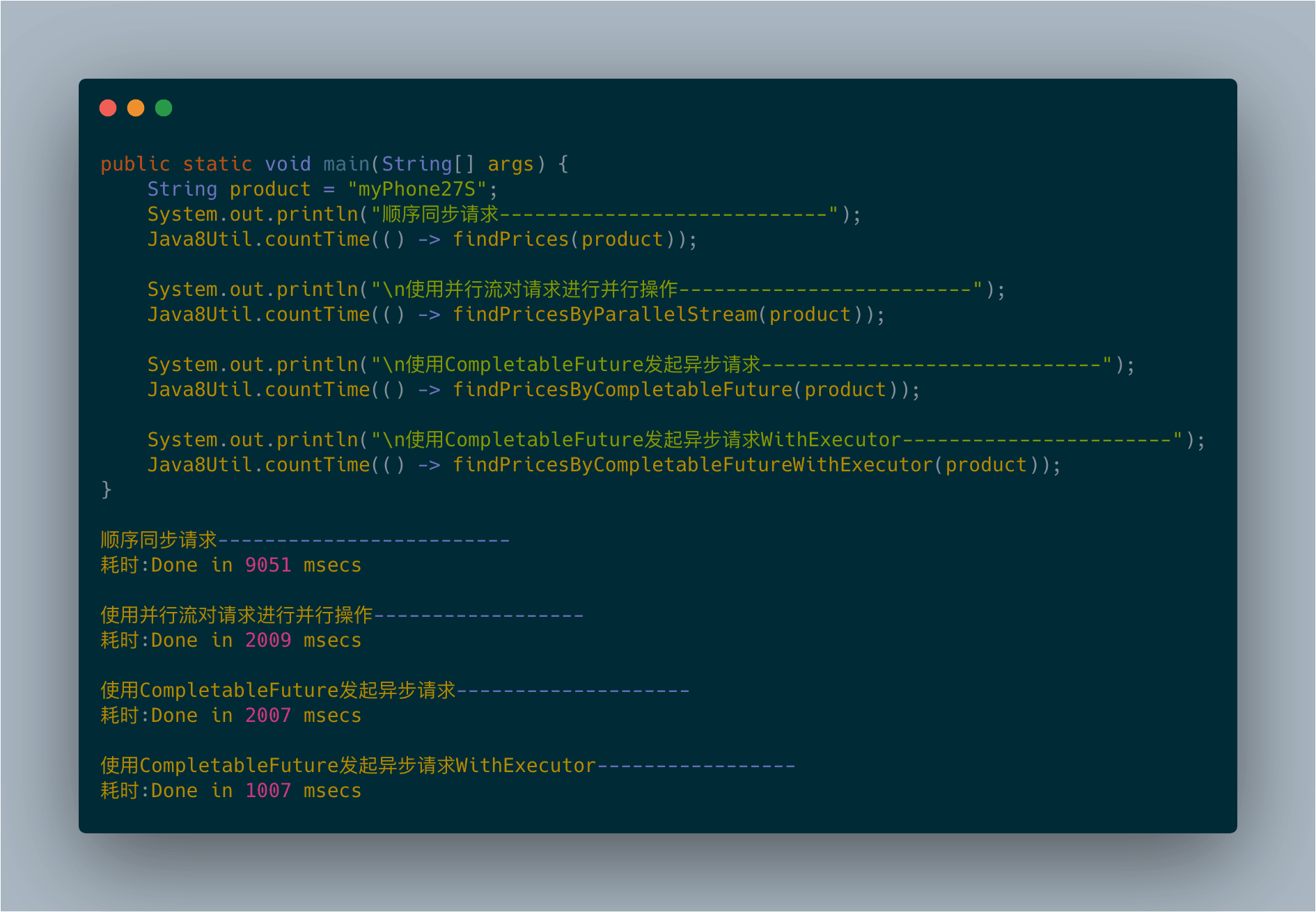
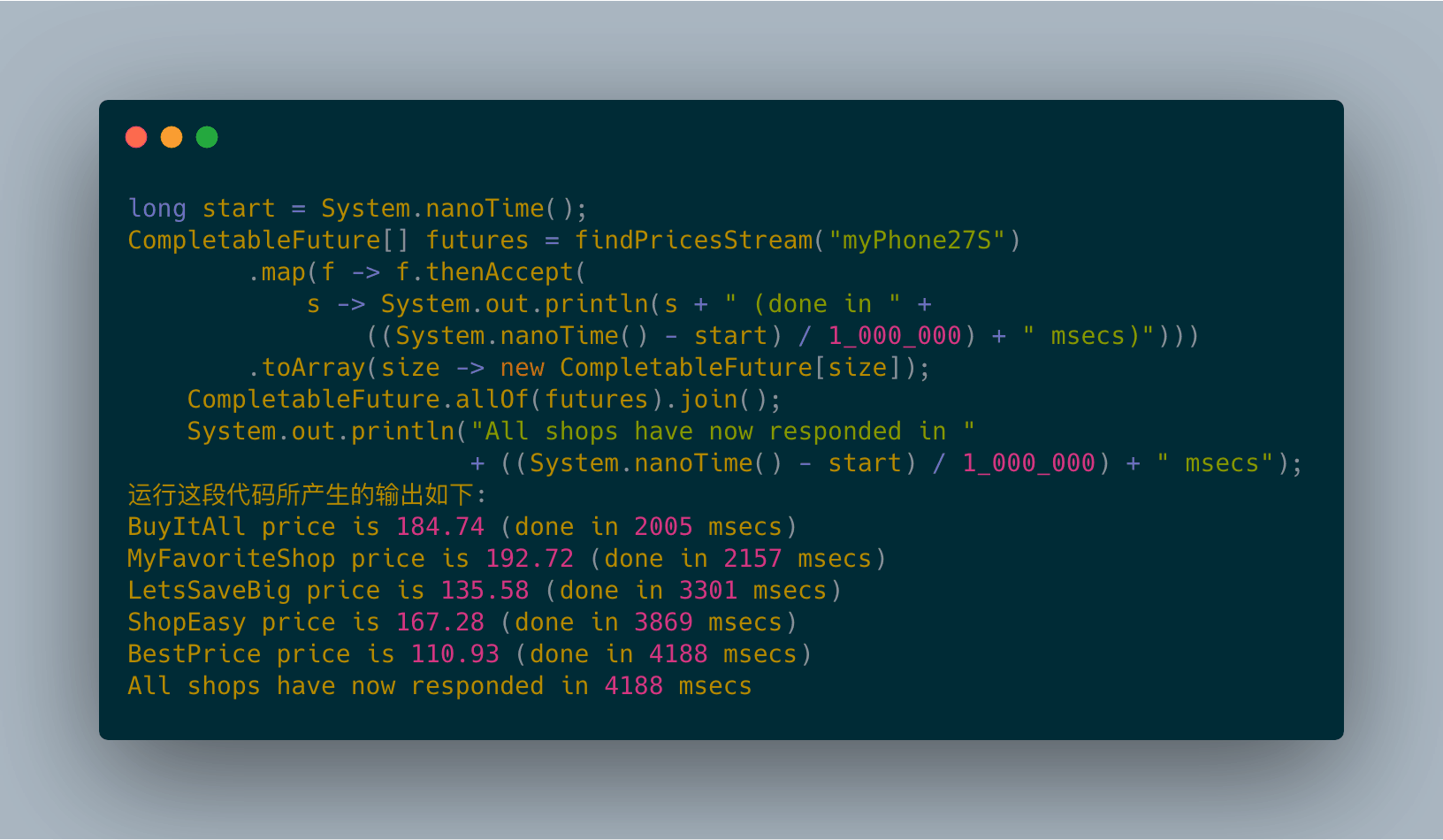
CompletableFuture版本的程序似乎比并行流版本的程序还快那么一点儿。但是最后这个版本也不太令人满意。它们看起来不相伯仲,究其原因都一样:它们内部采用的是同样的通用线程池,默认都使用固定数目的线程,具体线程数取决于Runtime.getRuntime().availableProcessors()的返回值。然而,CompletableFuture具有一定的优势,因为它允许你对执行器(Executor)进行配置,尤其是线程池的大小,让它以更适合应用需求的方式进行配置,满足程序的要求,而这是并行流API无法提供的。
顺序执行和并行执行的原理对比:
图11-4的上半部分展示了使用单一流水线处理流的过程,我们看到,执行的流程(以虚线标识)是顺序的。事实上,新的CompletableFuture对象只有在前一个操作完全结束之后,才能创建。与此相反,图的下半部分展示了如何先将CompletableFutures对象聚集到一个列表中(即图中以椭圆表示的部分),让对象们可以在等待其他对象完成操作之前就能启动。
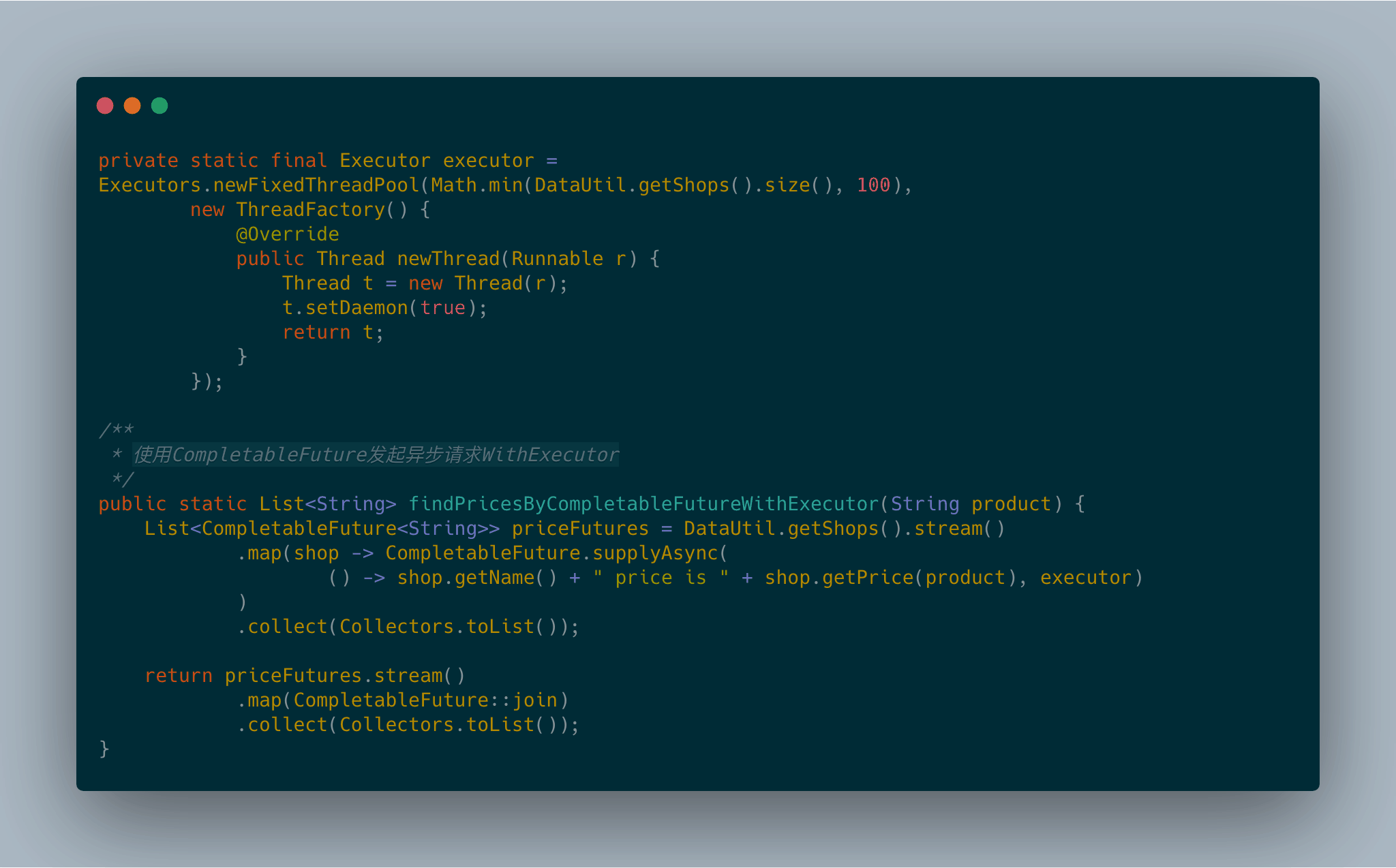
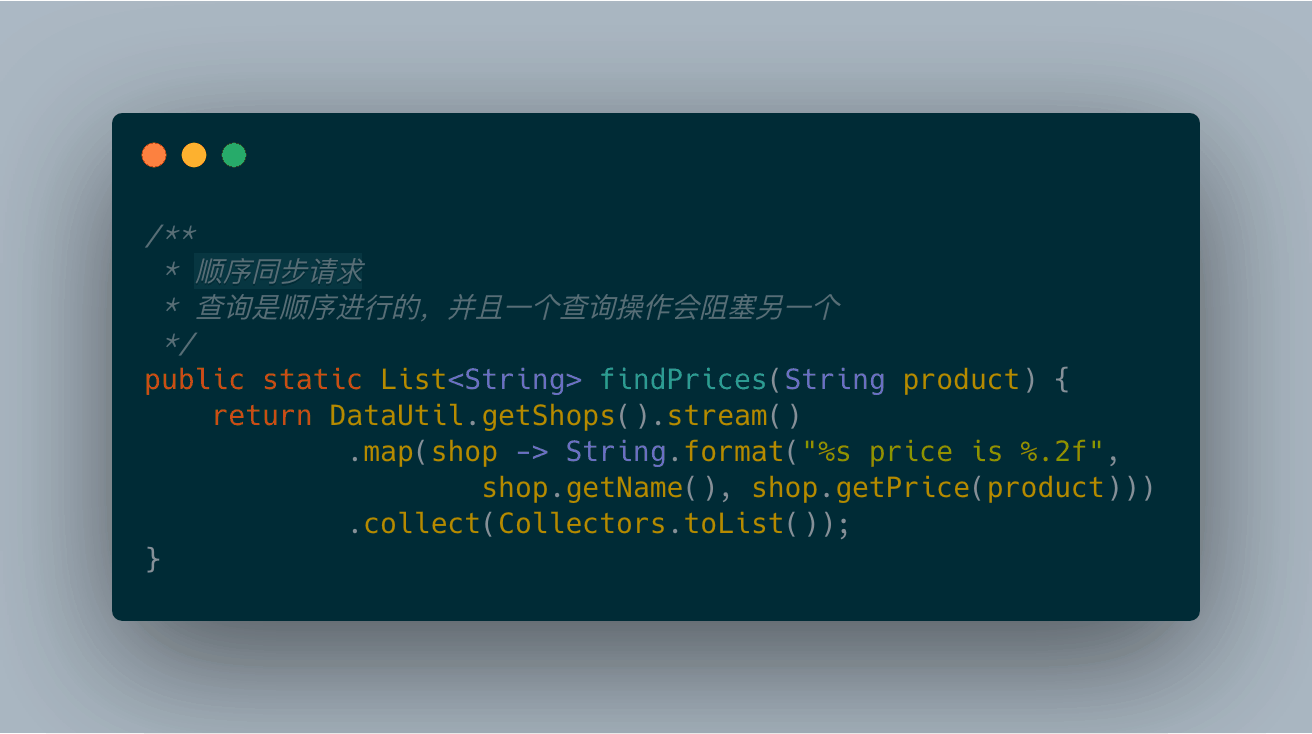
目前为止,你已经知道对集合进行并行计算有两种方式:要么将其转化为并行流,利用map这样的操作开展工作,要么枚举出集合中的每一个元素,创建新的线程,在CompletableFuture内对其进行操作。后者提供了更多的灵活性,你可以调整线程池的大小,而这能帮助你确保整体的计算不会因为线程都在等待I/O而发生阻塞。
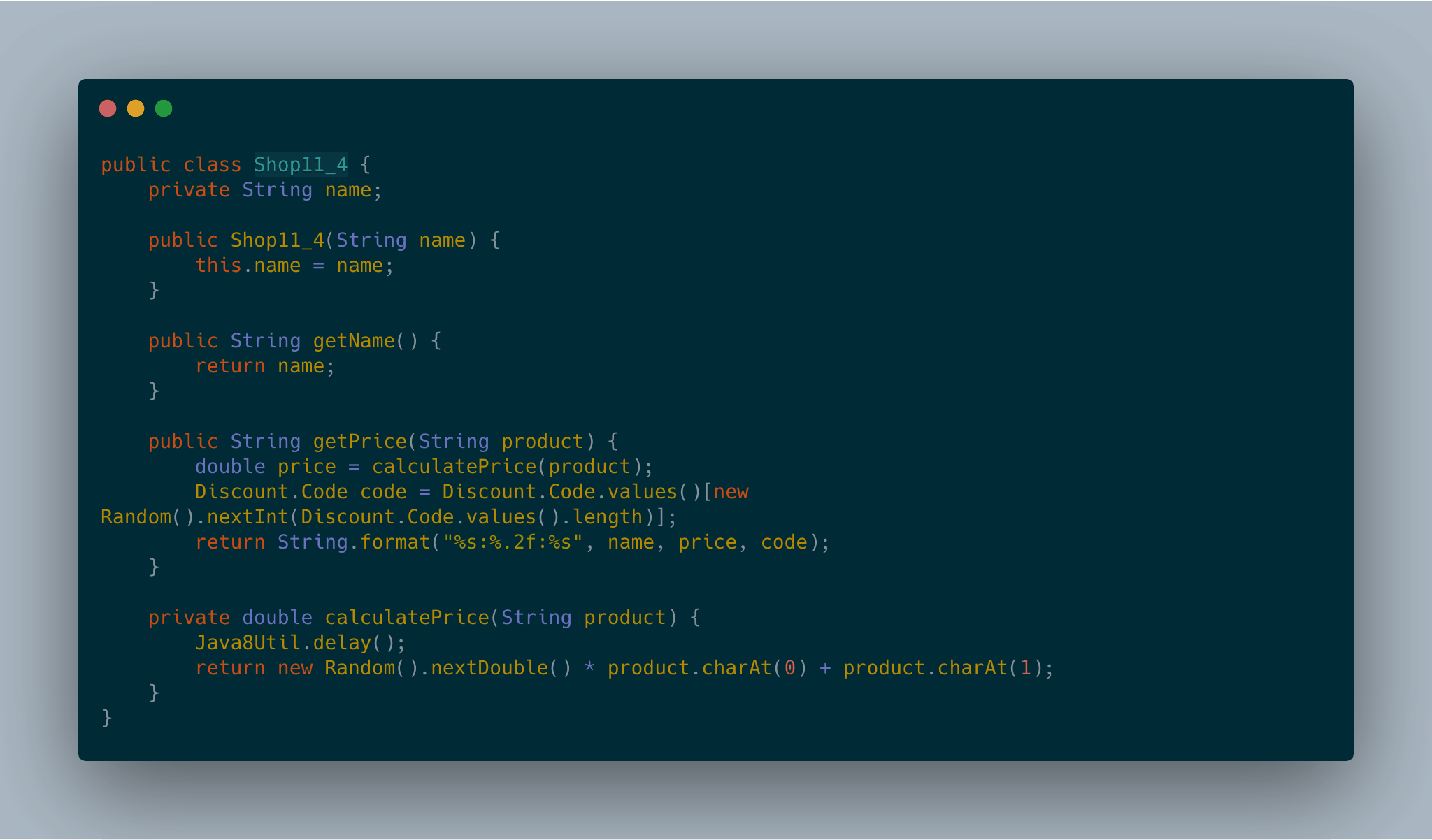
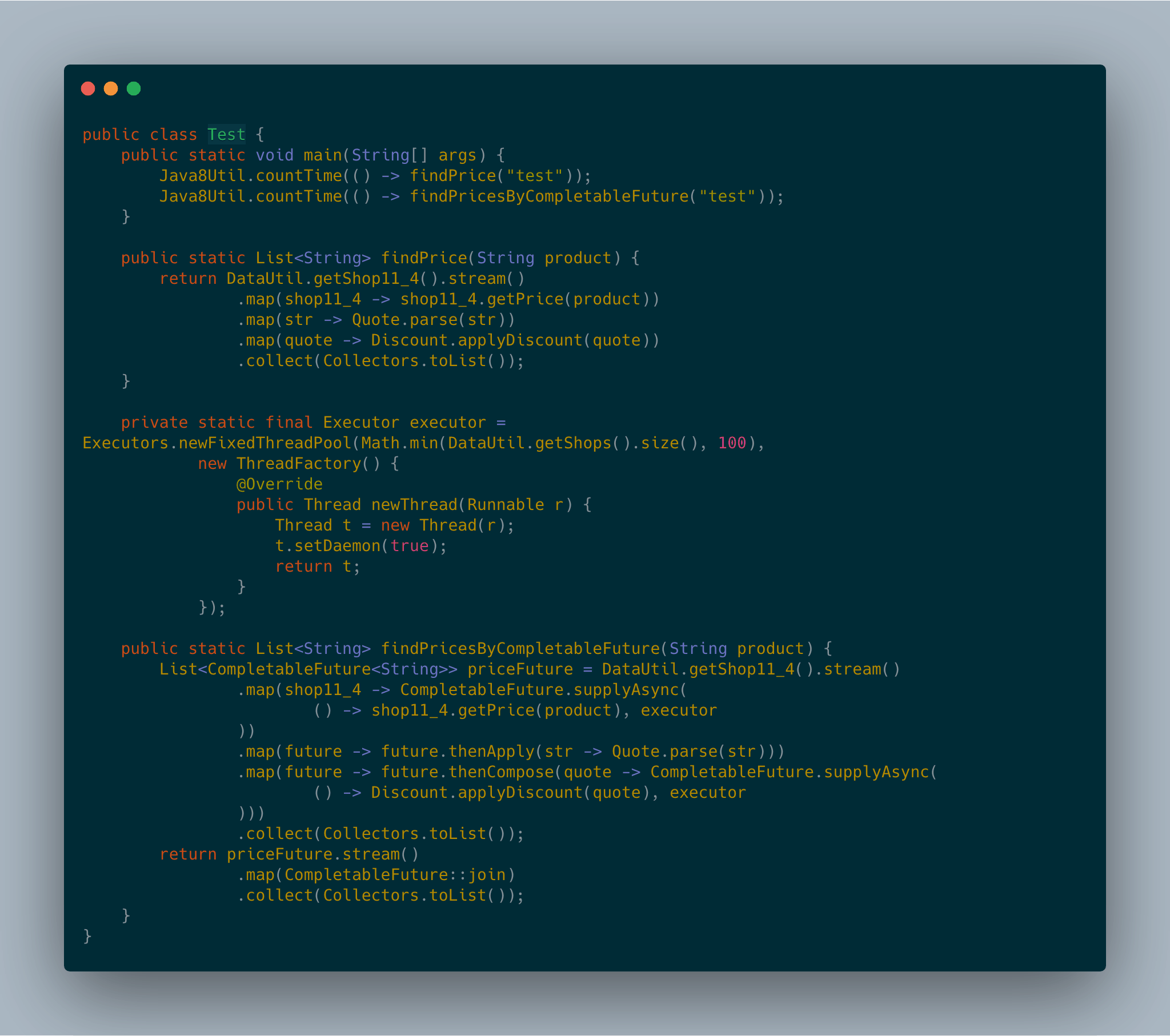
通过在shop构成的流上采用流水线方式执行三次map操作,我们得到了结果。
代码如图:

原理图: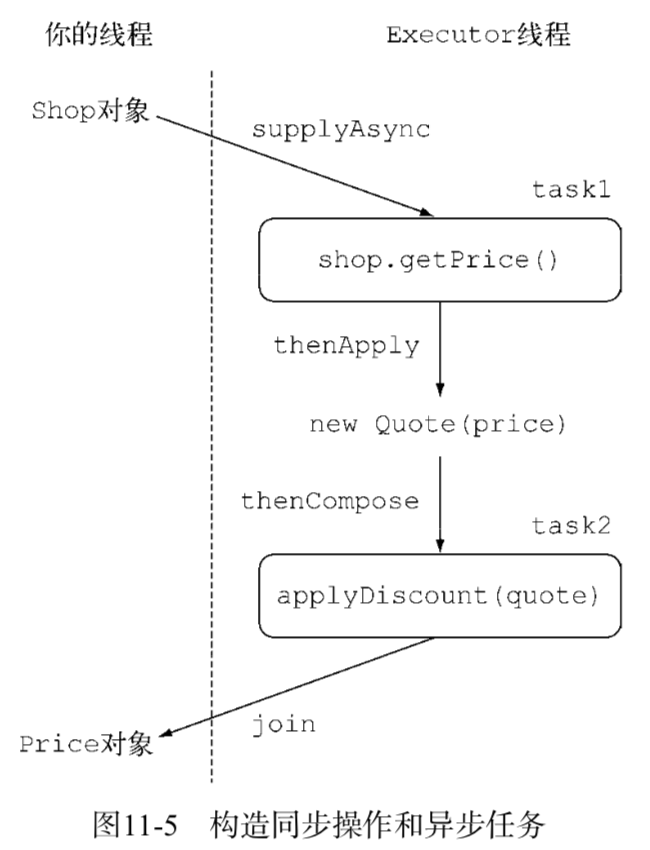
Java 8的CompletableFuture API提供了名为thenCompose的方法,它就是专门为这一目的而设计的,thenCompose方法允许你对两个异步操作进行流水线,第一个操作完成时,将其结果作为参数传递给第二个操作。换句话说,你可以创建两个CompletableFutures对象,对第一个CompletableFuture对象调用thenCompose,并向其传递一个函数。当第一个 CompletableFuture执行完毕后,它的结果将作为该函数的参数,这个函数的返回值是以第一 个CompletableFuture的返回做输入计算出的第二个CompletableFuture对象。thenCompose方法像CompletableFuture类中的其他方法一样,也提供了一个以Async后缀结尾的版本thenComposeAsync。通常而言,名称中不带Async的方法和它的前一个任务一样,在同一个线程中运行;而名称以Async结尾的方法会将后续的任务提交到一个线程池,所以每个任务是由不同的线程处理的。
将两个CompletableFuture对象结合起来,无论他们是否存在依赖。thenCombine方法,它接收名为BiFunction的第二参数,这个参数 定义了当两个CompletableFuture对象完成计算后,结果如何合并。同thenCompose方法一样, thenCombine方法也提供有一个Async的版本。这里,如果使用thenCombineAsync会导致BiFunction中定义的合并操作被提交到线程池中,由另一个任务以异步的方式执行。
代码图: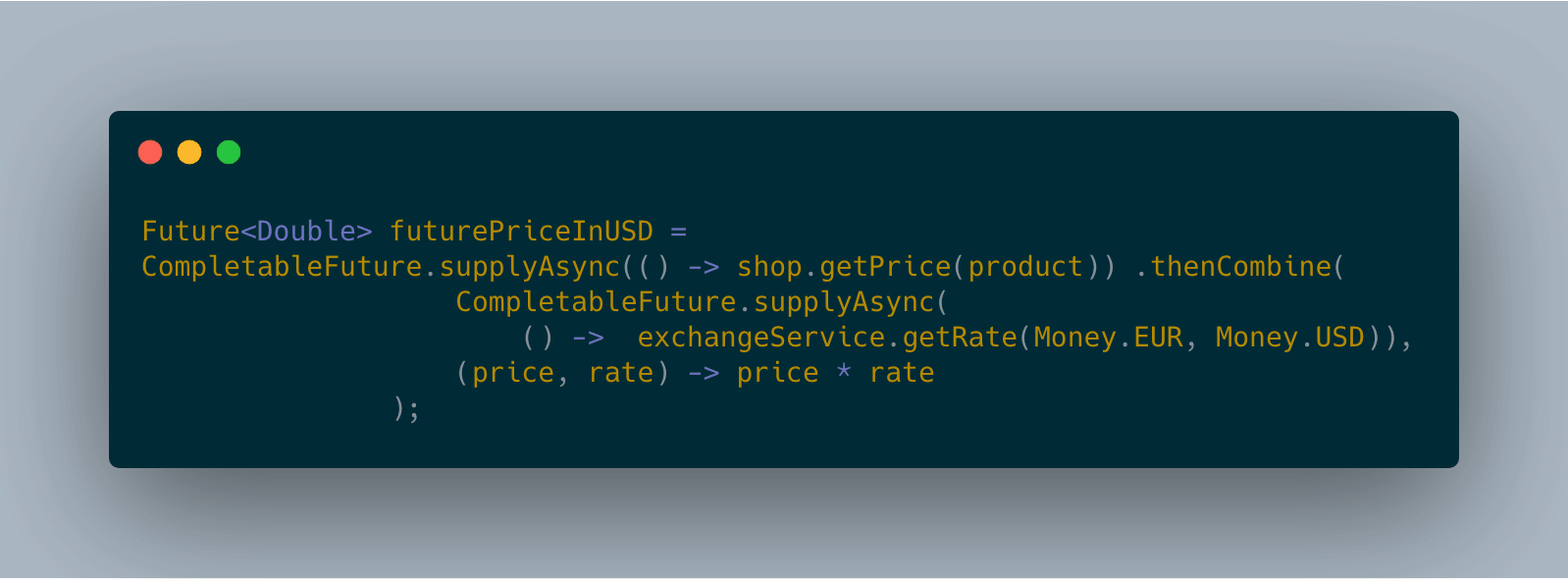
原理图:
Java 8的CompletableFuture通过thenAccept方法提供了这一功能,它接收 CompletableFuture执行完毕后的返回值做参数。thenAccept方法也提供 了一个异步版本,名为thenAcceptAsync。异步版本的方法会对处理结果的消费者进行调度, 从线程池中选择一个新的线程继续执行,不再由同一个线程完成CompletableFuture的所有任 务。因为你想要避免不必要的上下文切换,更重要的是你希望避免在等待线程上浪费时间,尽快响应CompletableFuture的completion事件,所以这里没有采用异步版本。
1965年,英国一位名为Tony Hoare的计算机科学家在设计ALGOL W语言时提出了null引用的想法。ALGOL W是第一批在堆上分配记录的类型语言之一。Hoare选择null引用这种方式,“只是因为这种方法实现起来非常容易”。虽然他的设计初衷就是要“通过编译器的自动检测机制,确保所有使用引用的地方都是绝对安全的”,他还是决定为null引用开个绿灯,因为他认为这是为“不存在的值”建模最容易的方式。很多年后,他开始为自己曾经做过这样的决定而后悔不已,把它称为“我价值百万的重大事物”。实际上,Hoare的这段话低估了过去五十年来数百万程序员为修复空引用所耗费的代价。近十年出现的大多数现代程序设计语言1,包括Java,都采用了同样的设计方式,其原因是为了与更老的语言保持兼容,或者就像Hoare曾经陈述的那样,“仅仅是因为这样实现起来更加容易”。
1 | public class Person { |
上面这段代码的问题就在于,如果person没有车,就会造成空指针异常。
简单来说就是在需要的地方添加null检查
1 | public String getCarInsuranceName(Person person) { |
上述代码不具备扩展性,同时还牺牲了代码的可读性。
1 | public String getCarInsuranceName(Person person) { |
这种模式中方法的退出点有四处,使得代码的维护异常艰难。
变量存在时,Optional类只是对类简单封装。变量不存在时,缺失的值会被建模成一个“空”的Optional对象,由方法Optional.empty()返回。Optional.empty()方法是一个静态工厂方法,它返回Optional类的特定单一实例。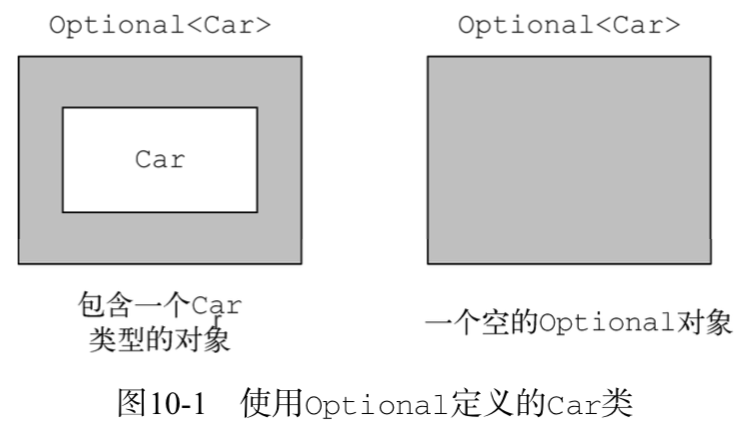
引入Optional类的意图并非要消除每一个null引用,相反的是,它的目标是帮助开发者更好地设计出普适的API。
正如前文已经提到,你可以通过静态工厂方法Optional.empty,创建一个空的Optional对象:
1 | Optional<Car> optCar = Optional.empty(); |
你还可以使用静态工厂方法Optional.of,依据一个非空值创建一个Optional对象:
1 | Optional<Car> optCar = Optional.of(car); |
如果car是一个null,这段代码会立即抛出一个NullPointerException,而不是等到你试图访问car的属性值时才返回一个错误。
最后,使用静态工厂方法Optional.ofNullable,你可以创建一个允许null值的Optional对象:
1 | Optional<Car> optCar = Optional.ofNullable(car); |
如果car是null,那么得到的Optional对象就是个空对象。
从对象中提取信息是一种比较常见的模式。
1 | String name = null; |
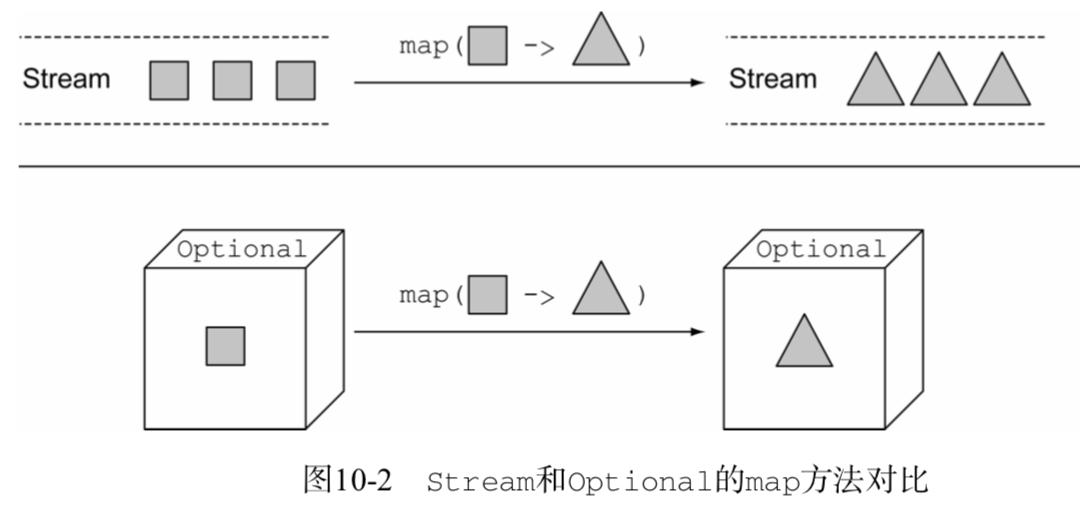
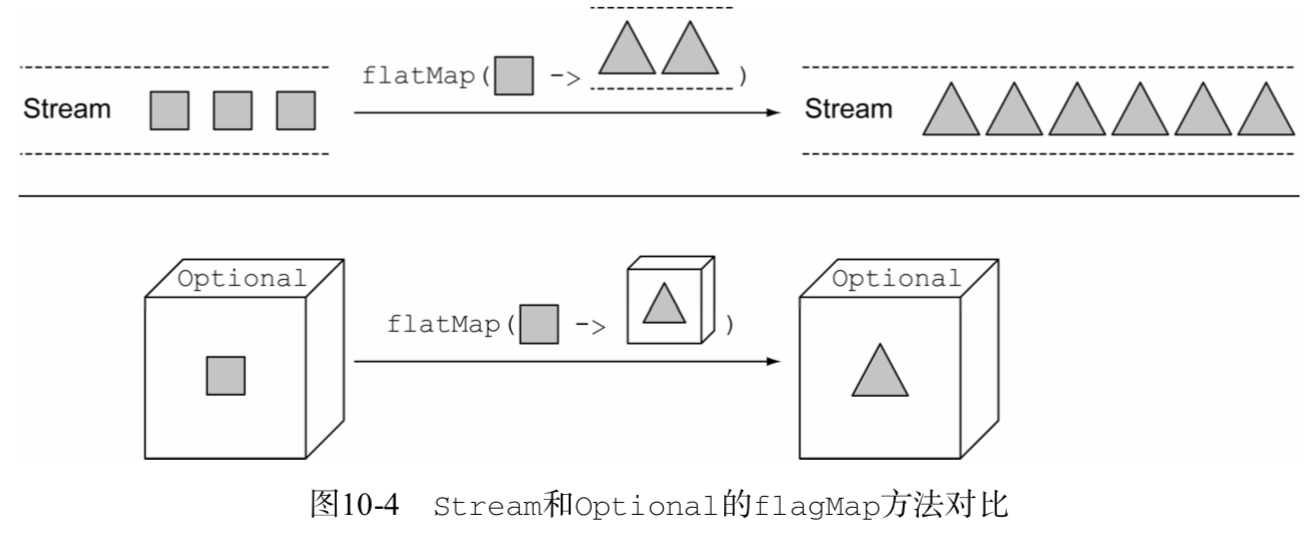
使用流时,flatMap方法接受一个函数作为参数,这个函数的返回值是另一个流。 这个方法会应用到流中的每一个元素,最终形成一个新的流的流。但是flagMap会用流的内容替换每个新生成的流。换句话说,由方法生成的各个流会被合并或者扁平化为一个单一的流。
1 | public String getCarInsuranceName(Optional<Person> person) { return person.flatMap(Person::getCar) |
1 | public Optional<Insurance> nullSafeFindCheapestInsurance(Optional<Person> person, Optional<Car> car) { |
filter方法接受一个谓词作为参数。如果Optional对象的值存在,并且它符合谓词的条件, filter方法就返回其值;否则它就返回一个空的Optional对象。
1 | Insurance insurance = ...; |
Optional类中的方法进行了分类和概括:

1 | Optional<Object> value = Optional.ofNullable(map.get("key")); |
每次你希望安全地对潜在为null的对象进行转换,将其替换为Optional对象时,都可以考虑使用这种方法。
1 | public static Optional<Integer> stringToInt(String s) { |
我们的建议是,你可以将多个类似的方法封装到一个工具类中,让我们称之为OptionalUtility。通过这种方式,你以后就能直接调用OptionalUtility.stringToInt方法,将String转换为一个Optional
1 | public int readDuration(Properties props, String name) { |
这一章中,你学到了以下的内容。
传统上,Java程序的接口是将相关方法按照约定组合到一起的方式。实现接口的类必须为接口中定义的每个方法提供一个实现,或者从父类中继承它的实现。
但是,一旦类库的设计者需要更新接口,向其中加入新的方法,这种方式就会出现问题。现实情况是,现存的实体类往往不在接口设计者的控制范围之内,这些实体类为了适配新的接口约定也需要进行修改。
由于Java 8的API在现存的接口上引入了非常多的新方法,这种变化带来的问题也愈加严重,一个例子就是前几章中使用过的 List 接口上的 sort 方法。
想象一下其他备选集合框架的维护人员会多么抓狂吧,像Guava和Apache Commons这样的框架现在都需要修改实现了 List 接口的所有类,为其添加sort 方法的实现。
Java 8为了解决这一问题引入了一种新的机制。Java 8中的接口现在支持在声明方法的同时提供实现,通过两种方式可以完成这种操作。其一,Java 8允许在接口内声明静态方法。
其二,Java 8引入了一个新功能,叫默认方法,通过默认方法你可以指定接口方法的默认实现。换句话说,接口能提供方法的具体实现。因此,实现接口的类如果不显式地提供该方法的具体实现,
就会自动继承默认的实现。这种机制可以使你平滑地进行接口的优化和演进。实际上,到目前为止你已经使用了多个默认方法。两个例子就是你前面已经见过的 List 接口中的 sort ,以及 Collection 接口中的 stream 。
第1章中 List 接口中的 sort 方法是Java 8中全新的方法,它的定义如下:
1 | default void sort(Comparator<? super E> c){ |
请注意返回类型之前的新 default 修饰符。通过它,我们能够知道一个方法是否为默认方法。这里 sort 方法调用了 Collections.sort 方法进行排序操作。由于有了这个新的方法,我们现在可以直接通过调用 sort ,对列表中的元素进行排序。
1 | List<Integer> numbers = Arrays.asList(3, 5, 1, 2, 6); |
不过除此之外,这段代码中还有些其他的新东西。我们调用了Comparator.naturalOrder 方法。这是 Comparator 接口的一个全新的静态方法,它返回一个Comparator 对象,并按自然序列对其中的元素进行排序(即标准的字母数字方式排序)。
第4章中的 Collection 中的 stream 方法的定义如下:
1 | default Stream<E> stream() { |
我们在之前的几章中大量使用了该方法来处理集合,这里 stream 方法中调用了SteamSupport.stream 方法来返回一个流。你注意到 stream 方法的主体是如何调用 spliterator 方法的了吗?它也是 Collection 接口的一个默认方法。
接口和抽象类还是有一些本质的区别,我们在这一章中会针对性地进行讨论。
简而言之,向接口添加方法是诸多问题的罪恶之源;一旦接口发生变化,实现这些接口的类往往也需要更新,提供新添方法的实现才能适配接口的变化。如果你对接口以及它所有相关的实现有完全的控制,这可能不是个大问题。但是这种情况是极少的。这就是引入默认方法的目的:它让类可以自动地继承接口的一个默认实现。
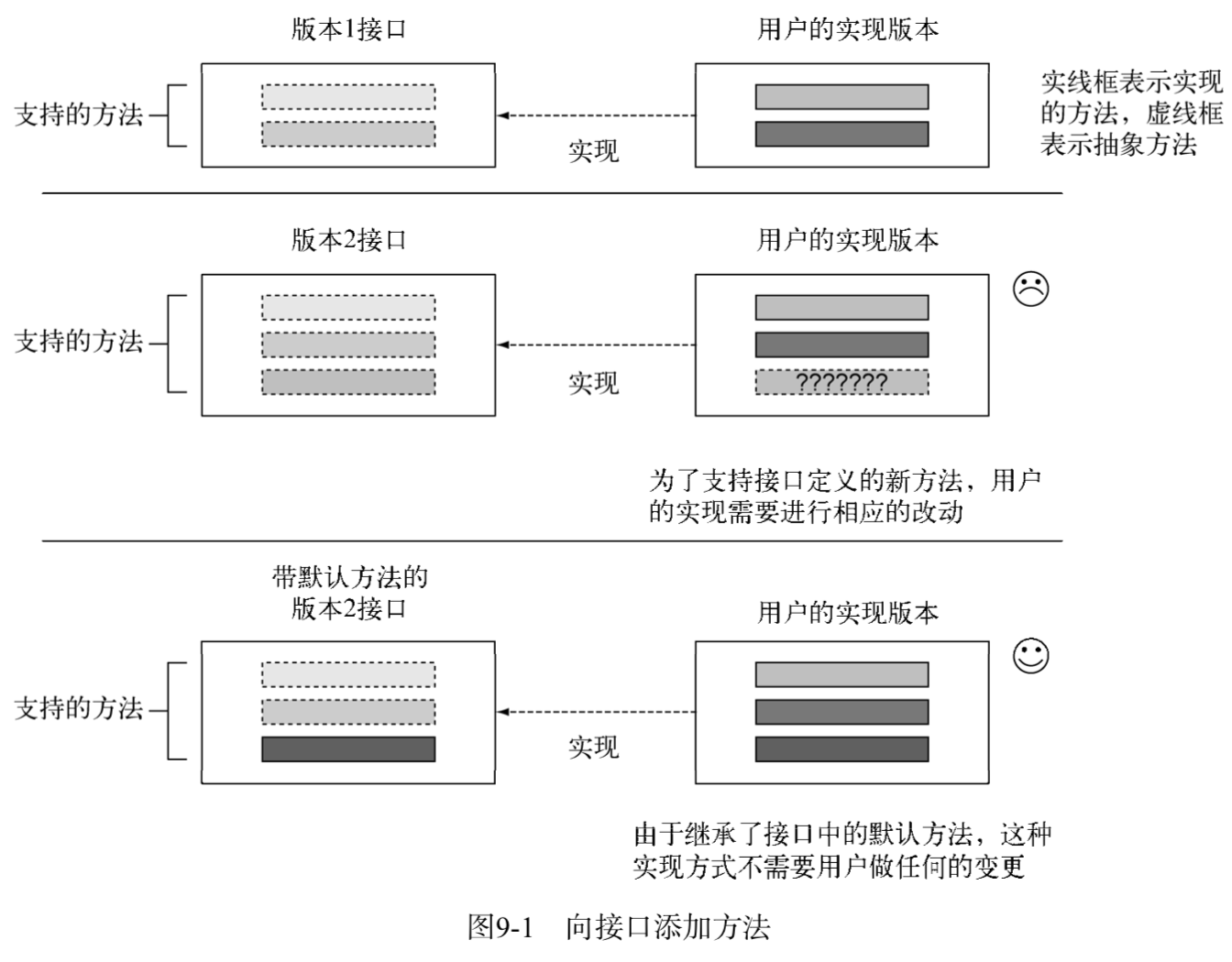
Resizable 接口的最初版本提供了下面这些方法:
1 | public interface Drawable { |
库上线使用几个月之后,你收到很多请求,要求你更新 Resizable 的实现,让 Square Triangle 以及其他的形状都能支持 setRelativeSize 方法。为了满足这些新的需求,你发布了第二版API。
1 | public interface Resizable extends Drawable { |
对 Resizable 接口的更新导致了一系列的问题。首先,接口现在要求它所有的实现类添加setRelativeSize 方法的实现。但是用户最初实现的 Ellipse 类并未包含 setRelativeSize方法。向接口添加新方法是二进制兼容的,这意味着如果不重新编译该类,即使不实现新的方法,现有类的实现依旧可以运行。不过,用户可能修改他的游戏,在他的 Utils.paint 方法中调用setRelativeSize 方法,因为 paint 方法接受一个 Resizable 对象列表作为参数。如果传递的是一个 Ellipse 对象,程序就会抛出一个运行时错误,因为它并未实现 setRelativeSize 方法:
1 | Exception in thread "main" java.lang.AbstractMethodError:lambdasinaction.chap9.Ellipse.setRelativeSize(II)V |
其次,如果用户试图重新编译整个应用(包括 Ellipse 类),他会遭遇下面的编译错误:
1 | Error:(9, 8) java: com.lujiahao.learnjava8.chapter9.Ellipse不是抽象的, 并且未覆盖 |
这就是默认方法试图解决的问题。它让类库的设计者放心地改进应用程序接口,无需担忧对遗留代码的影响,这是因为实现更新接口的类现在会自动继承一个默认的方法实现。
变更对Java程序的影响大体可以分成三种类型的兼容性,分别是:
默认方法由 default 修饰符修饰,并像类中声明的其他方法一样包含方法体。比如,你可以像下面这样在集合库中定义一个名为Sized 的接口,在其中定义一个抽象方法 size ,以及一个默认方法 isEmpty :
1 | public interface Sized { |
这样任何一个实现了 Sized 接口的类都会自动继承 isEmpty 的实现。因此,向提供了默认实现的接口添加方法就不是源码兼容的。
默认方法在Java 8的API中已经大量地使用了。本章已经介绍过我们前一章中大量使用的 Collection 接口的 stream 方法就是默认方法。 List 接口的 sort 方法也是默认方法。第3章介绍的很多函数式接口,比如 Predicate 、 Function 以及 Comparator 也引入了新的默认方法,比如 Predicate.and 或者 Function.andThen (记住,函数式接口只包含一个抽象方法,默认方法是种非抽象方法)。
类实现了接口,不过却刻意地将一些方法的实现留白。我们以Iterator 接口为例来说。 Iterator 接口定义了 hasNext 、 next ,还定义了 remove 方法。Java 8之前,由于用户通常不会使用该方法, remove 方法常被忽略。因此,实现 Interator 接口的类通常会为 remove 方法放置一个空的实现,这些都是些毫无用处的模板代码。采用默认方法之后,你可以为这种类型的方法提供一个默认的实现,这样实体类就无需在自己的实现中显式地提供一个空方法。比如,在Java 8中, Iterator 接口就为 remove 方法提供了一个默认实现,如下所示:
1 | public interface Iterator<E> { |
默认方法让之前无法想象的事儿以一种优雅的方式得以实现,即行为的多继承。这是一种让类从多个来源重用代码的能力。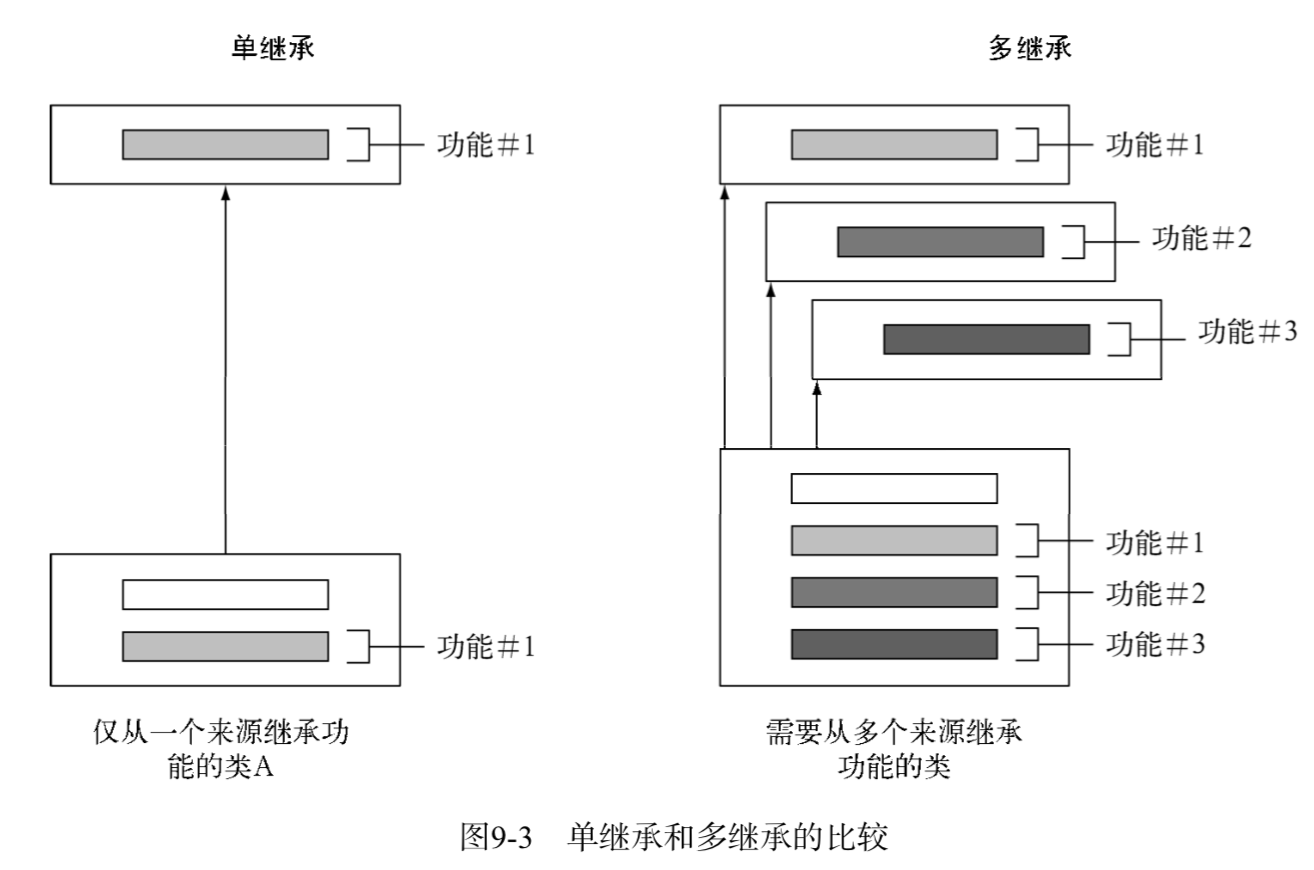
Java的类只能继承单一的类,但是一个类可以实现多接口。要确认也很简单,下面是Java API中对 ArrayList 类的定义:
1 | public class ArrayList<E> extends AbstractList<E> |
这个例子中 ArrayList 继承了一个类,实现了六个接口。因此 ArrayList 实际是七个类型的直接子类,分别是: AbstractList 、 List 、 RandomAccess 、 Cloneable 、 Serializable 、Iterable 和 Collection 。所以,在某种程度上,我们早就有了类型的多继承。
由于Java 8中接口方法可以包含实现,类可以从多个接口中继承它们的行为(即实现的代码)。让我们从一个例子入手,看看如何充分利用这种能力来为我们服务。保持接口的精致性和正交性能帮助你在现有的代码基上最大程度地实现代码复用和行为组合。
假设你需要为你正在创建的游戏定义多个具有不同特质的形状。有的形状需要调整大小,但是不需要有旋转的功能;有的需要能旋转和移动,但是不需要调整大小。这种情况下,你怎么设计才能尽可能地重用代码?
你可以定义一个单独的 Rotatable 接口,并提供两个抽象方法 setRotationAngle 和getRotationAngle ,如下所示:
1 | public interface Rotatable { |
这种方式和模板设计模式有些相似,都是以其他方法需要实现的方法定义好框架算法。
现在,实现了 Rotatable 的所有类都需要提供 setRotationAngle 和 getRotationAngle的实现,但与此同时它们也会天然地继承 rotateBy 的默认实现。
类似地,你可以定义之前看到的两个接口 Moveable 和 Resizable 。它们都包含了默认实现。下面是 Moveable 的代码:
1 | public interface Moveable { |
通过组合这些接口,你现在可以为你的游戏创建不同的实体类。比如, Monster 可以移动、旋转和缩放。
1 | public class Monster implements Rotatable, Moveable, Resizable { |
Monster 类会自动继承 Rotatable 、 Moveable 和 Resizable 接口的默认方法。这个例子中,Monster 继承了 rotateBy 、 moveHorizontally 、 moveVertically 和 setRelativeSize 的实现。
你现在可以直接调用不同的方法:
1 | Monster m = new Monster(); |
像你的游戏代码那样使用默认实现来定义简单的接口还有另一个好处。假设你需要修改moveVertically 的实现,让它更高效地运行。你可以在 Moveable 接口内直接修改它的实现,所有实现该接口的类会自动继承新的代码(这里我们假设用户并未定义自己的方法实现)。
通过前面的介绍,你已经了解了默认方法多种强大的使用模式。不过也可能还有一些疑惑:如果一个类同时实现了两个接口,这两个接口恰巧又提供了同样的默认方法签名,这时会发生什么情况?类会选择使用哪一个方法?这些问题,我们会在接下来的一节进行讨论。
随着默认方法在Java 8中引入,有可能出现一个类继承了多个方法而它们使用的却是同样的函数签名。这种情况下,类会选择使用哪一个函数?接下来的例子主要用于说明容易出问题的场景,并不表示这些场景在实际开发过程中会经常发生。
1 | public interface A { |
此外,你可能早就对C++语言中著名的菱形继承问题有所了解,菱形继承问题中一个类同时继承了具有相同函数签名的两个方法。到底该选择哪一个实现呢? Java 8也提供了解决这个问题的方案。请接着阅读下面的内容。
如果一个类使用相同的函数签名从多个地方(比如另一个类或接口)继承了方法,通过三条规则可以进行判断。
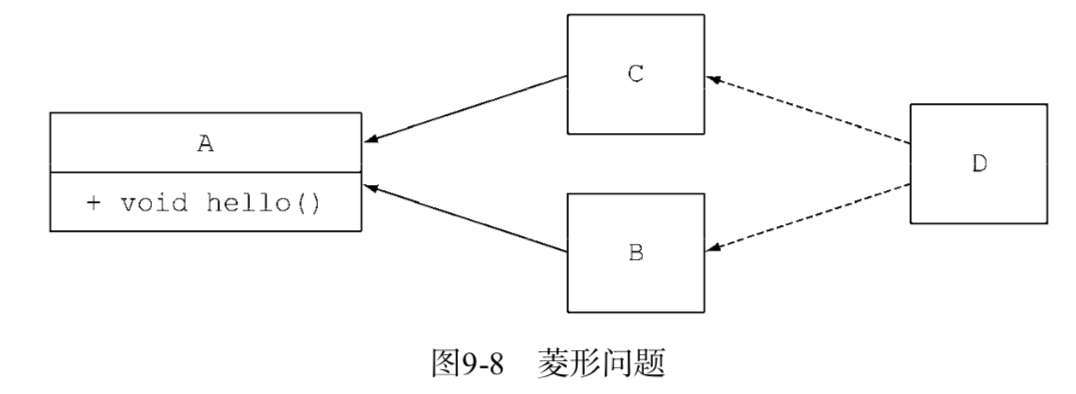
了解即可
我们会介绍几种方法,帮助你重构代码,以适配使用Lambda表达式,让你的代码具备更好的可读性和灵活性。除此之外,我们还会讨论目前比较流行的几种面向对象的设计模式,
包括策略模式、模板方法模式、观察者模式、责任链模式,以及工厂模式,在结合Lambda表达式之后变得更简洁的情况。最后,我们会介绍如何测试和调试使用Lambda表达式和Stream API的代码。
Java 8的新特性也可以帮助提升代码的可读性:
利用Lambda表达式、方法引用以及Stream改善程序代码的可读性:
将实现单一抽象方法的匿名类转换为Lambda表达式
1 | // 传统的方式,使用匿名类 |
匿名 类和Lambda表达式中的this和super的含义是不同的。在匿名类中,this代表的是类自身,但是在Lambda中,它代表的是包含类。其次,匿名类可以屏蔽包含类的变量,而Lambda表达式不能(它们会导致编译错误),如下面这段代码:
1 | int a = 10; |
在涉及重的上下文里,将匿名类转换为Lambda表达式可能导致最终的代码更加晦涩。实际上,匿名类的类型是在初始化时确定的,而Lambda的类型取决于它的上下文。通过下面这个例子,我们可以了解问题是如何发生的。我们假设你用与Runnable同样的签名声明了一个函数接口,我们称之为Task:
1 | interface Task{ |
目前大多数的集成开发环境,比如NetBeans和IntelliJ都支持这种重构,它们能自动地帮你检查,避免发生这些问题。
1 | Map<CaloricLevel, List<Dish>> dishesByCaloricLevel = |
将Lambda表达式的内容抽取到一个单独的方法中,将其作为参数传递给groupingBy方法。变换之后,代码变得更加简洁,程序的意图也更加清晰了。
1 | Map<CaloricLevel, List<Dish>> dishesByCaloricLevel = menu.stream().collect(groupingBy(Dish::getCaloricLevel)); |
我们建议你将所有使用迭代器这种数据处理模式处理集合的代码都转换成Stream API的方式。为什么呢?
Stream API能更清晰地表达数据处理管道的意图。除此之外,通过短路和延迟载入以及利用第7章介绍的现代计算机的多核架构,我们可以对Stream进行优化。
1 | // 命令式版本 |
没有函数式接口就无法使用Lambda表达式,因此代码中需要引入函数式接口。引入函数式接口的两种通用模式:
使用Lambda表达式后,很多现存的略显臃肿的面向对象设计模式能够用更精简的方式实现了。这一节中,我们会针对五个设计模式展开讨论,它们分别是:
策略模式代表了解决一类算法的通用解决方案,你可以在运行时选择使用哪种方案。策略模式包含三部分内容,如图所示。

1 | public interface ValidationStrategy { |
模板 方法模式在你“希望使用这个算法,但是需要对其中的某些行进行改进,才能达到希望的效果” 时是非常有用的。
1 | public abstract class OnlineBanking { |
观察者模式是一种比较常见的方案,某些事件发生时(比如状态转变),如果一个对象(通常我们称之为主题)需要自动地通知其他多个对象(称为观察者),就会采用该方案。
1 | public interface Observer { |
责任链模式是一种创建处理对象序列(比如操作序列)的通用方案。一个处理对象可能需要在完成一些工作之后,将结果传递给另一个对象,这个对象接着做一些工作,再转交给下一个处理对象,以此类推。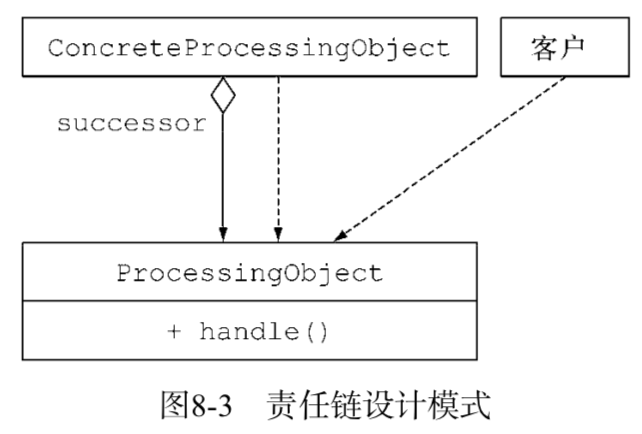
1 | public abstract class ProcessingObject<T> { |
使用工厂模式,你无需向客户暴露实例化的逻辑就能完成对象的创建。
1 | public interface Product {} |
略
1 | public class Debugging{ 11 public static void main(String[] args) { |
我们需要特别注意,涉及Lambda表达式的栈可能非常难理解。这是Java编译器未来版本可以改进的一个方面。
peek的设计初衷就是在流的每个元素恢复运行之前,插入执行一个动作。但是它不像forEach那样恢复整个流的运行,而是在一个元素上完成操作之后,它只会将操作顺承到流水线中的下一个操作。图8-4解释了peek的操作流程。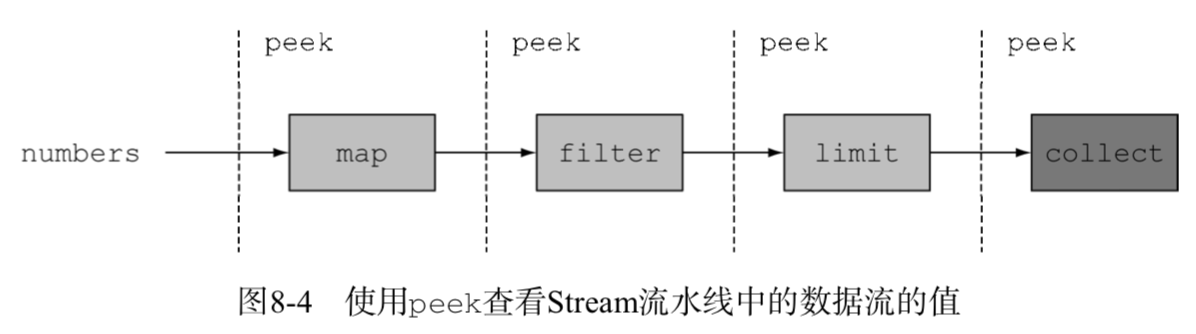
1 | List<Integer> result = numbers.stream() |