Listener-监听器
TODO:这一部分不太明白,需要后面在好好看看吧
TODO:这一部分不太明白,需要后面在好好看看吧

select ..... limit 参数1,参数2;
参数1 ,表示开始索引,从0开始。startIndex ,算法 (pageNum - 1) * pageSize
参数2 ,表示每页显示个数。pageSize/**
* 查询所有--分页查询
*/
private void findAllWithPage(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException{
try {
// 1.获得数据并封装
// 获得当前页码
String pageNumStr = request.getParameter("pageNum");
int pageNum = 1;
try {
// 这种处理方式可以防止在地址栏里面输入非数字导致转化异常
pageNum = Integer.parseInt(pageNumStr);
} catch (Exception e){
}
// * 每页显示个数(固定值)
int pageSize = 5;
// 2.通知service查询所有
CustomerServeice customerServeice = new CustomerServiceImpl();
PageBean<Customer> pageBean = customerServeice.findAllCustomerWithPage(pageNum, pageSize);
// 3.显示
// 存放到request作用域中--每一次查询都是新的数据
request.setAttribute("pageBean",pageBean);
// servlet到jsp中显示,一次请求需要使用请求转发
request.getRequestDispatcher("/pages/show_all_page.jsp").forward(request,response);
} catch (Exception e){
// 1.打印日志
e.printStackTrace();
// 2.请求转发到消息界面
request.setAttribute("msg","查询失败,请稍后重试.");
request.getRequestDispatcher("/pages/message.jsp").forward(request,response);
}
}@Override
public PageBean<Customer> findAllCustomerWithPage(int pageNum, int pageSize) {
// 一般分页的逻辑是要在service里面来写
// 创建PageBean封装分页所有的数据,并将封装后的数据返回
// 1.查询总记录数
int totalRecord = customerDao.getTotalRecord();
// 2.创建PageBean
PageBean<Customer> pageBean = new PageBean<>(pageNum,pageSize,totalRecord);
// 3.查询结果
List<Customer> data = customerDao.findAll(pageBean.getStartIndex(), pageBean.getPageSize());
pageBean.setData(data);
return pageBean;
}@Override
public List<Customer> findAll(int startIndex, int pageSize) {
try {
String sql = "select * from t_customer limit ?,?";
Object[] params = {startIndex,pageSize};
return runner.query(sql,new BeanListHandler<Customer>(Customer.class),params);
} catch (Exception e){
throw new DaoException(e);
}
}当前${pageBean.pageNum}页,共${pageBean.totalPage}页,总条数${pageBean.totalRecord}条<br/>
<c:url value="${pageContext.request.contextPath}/CustomerServlet" var="baseUrl">
<c:param name="method" value="findAllWithPage"></c:param>
<c:param name="pageNum" value=""></c:param>
</c:url>
<c:if test="${pageBean.pageNum > 1}">
<a href="${baseUrl}1">首页</a>
<a href="${baseUrl}${pageBean.pageNum-1}">上一页</a>
</c:if>
<c:forEach begin="${pageBean.start}" end="${pageBean.end}" var="num">
<a href="${baseUrl}${num}">${num}</a>
</c:forEach>
<c:if test="${pageBean.pageNum < pageBean.totalPage}">
<a href="${baseUrl}${pageBean.pageNum+1}">下一页</a>
<a href="${baseUrl}${pageBean.totalPage}">尾页</a>
</c:if>/**
* 分页的封装类
* 封装的两种思路:
* -- 集合Map(Android中常见的请求参数的封装)
* -- 自定义JavaBean对象
* Created by lujiahao on 2016/7/25.
*/
public class PageBean<T> {
// 分页必备选项,为下面计算提供数据
private int pageNum; // 当前页(第几页)
private int pageSize; // 每页显示个数
private int totalRecord; // 总记录数(总条数)---这个数据需要通过查询来获得
// 通过计算获得的数据
private int startIndex; // 分页开始的索引
private int totalPage; // 总分页数
// 分页查询的结果
private List<T> data; // 查询分页的数据--使用泛型的目的是为了方便复用
// 导航条动态显示 首页 上一页 1 2 3 4 下一页 尾页
private int start; // 循环开始
private int end; // 循环结束
public PageBean(int pageNum, int pageSize, int totalRecord) {
// 构造方法中初始化三个必备选项
this.pageNum = pageNum;
this.pageSize = pageSize;
this.totalRecord = totalRecord;
// 处理地址栏输入负页数
if (this.pageNum < 1) {
this.pageNum = 1;
}
// 计算分页开始的索引:(当前页 - 1) * 每页显示个数
this.startIndex = (this.pageNum - 1) * this.pageSize;
// 计算总分页数
if (this.totalRecord % this.pageSize == 0){
// 能整除,总分页数 = 总记录数 / 每页显示个数
this.totalPage = this.totalRecord / this.pageSize;
} else {
// 不能整除,需要加一页用来存不够一页的数据
this.totalPage = this.totalRecord / this.pageSize + 1;
}
// 上面的快捷算法---暂时理解不了啊
//this.totalPage = (this.totalRecord + (this.pageSize - 1)) / this.pageSize;
// 导航条动态显示 默认显示10页
this.start = 1;
this.end = 10;
// 总页数不够10页
if (this.totalPage <= 10){
this.end = this.totalPage;
} else {
// 总页数大于10页
// 页数要求 前五后四
this.start = this.pageNum -5;
this.end = this.pageNum +4;
// 当pageNum=1时,其实页数至少是1
if (this.start < 1){
this.start = 1;
this.end = 10;
}
// 当pageNum到最后一页事
if (this.end > this.totalPage){
this.end = this.totalPage;
this.start = this.totalPage -9; // 9 = 5 + 4
}
}
}
...get/set
}容错的处理非常巧妙:
这是在Servlet中的处理方式
String pageNumStr = request.getParameter("pageNum");
int pageNum = 1;
try {
// 这种处理方式可以防止在地址栏里面输入非数字导致转化异常
pageNum = Integer.parseInt(pageNumStr);
} catch (Exception e){
}这是在PageBean中的处理方式
// 处理地址栏输入负页数
if (this.pageNum < 1) {
this.pageNum = 1;
}Statement 和 PreparedStatement 都提供批处理。
批处理:批量处理sql语句。
Statement的批处理,可以一次性执行不同的sql语句。应用场景:系统初始化(创建数据库,创建不同表)
PreparedStatement 的批处理,只能执行一条sql语句,实际参数可以批量。应用场景:数据的初始化
addBatch(sql) ,给批处理缓存中添加sql语句。
clearBatch(); 清空批处理缓存。
executeBatch() , 执行批处理缓存所有的sql语句。注意:执行完成之后缓存中的内容仍然存在。addBatch() , 将实际参数批量设置缓存中。注意:获得预处理之前必须提供sql语句。
mysql 默认没开启批处理。
通过URL之后参数开启, ?rewriteBatchedStatements = true性能:read uncommitted > read committed > repeatable read > serializable
安全:read uncommitted < read committed < repeatable read < serializablemysql 默认事务提交的,及每执行一条sql语句就是一个事务。
扩展:oracle事务默认不提交,需要手动提交。
Savepoint 保存点,用于记录程序执行位置,方便可以随意回滚指定的位置。spring 事务的传播行为
AB整体(必须),CD整体(可选)
Savepoint savepoint = null;
try{
// 1 开启事务
conn.setAutoCommit(false);
A
B
// 记录保存点
savepoint = conn.setSavepoint();
C
D
//2 提交ABCD
conn.commit();
} catch(){
if(savepoint != null){
//CD 有异常,回滚到CD之前
conn.rollback(savepoint);
// 提交AB
conn.commit();
} else {
//AB有异常 ,回滚到最开始处
conn.rollback();
}
}A 查询数据,username = ‘jack’ ,password = ‘1234’
B 查询数据,username=”jack”, password=”1234”
A 更新用户名 username=”rose”,password=’1234’ –> username=”rose”,password=”1234”
B 更新密码 password=”9999” ,username=”jack” –> username=”jack”,password=’9999’
丢失更新:最后更新数据,将前面更新的数据覆盖了。
乐观锁:丢失更新肯定不会发生。
给表中添加一个字段(标识),用于记录操作版本。
username="jack",password="1234",version="1" ,比较版本号,如果一样,修改版本自动+1.。如果不一样,必须先查询,再更新。悲观锁:丢失更新肯定会发生。采用数据库锁机制。
读锁:共享锁,大家可以一起读。
select .... from .... lock in share mode;
写锁:排他锁,只能一个进行写,不能有其他锁(写、读),所有更新update操作丢将自动获得写锁。
select ... from ... for update;注意:数据库的锁,必须在事务中使用。
只要事务操作完成(commit|rollback|超时)自动释放锁
1.为什么使用连接池:连接Connection 创建与销毁 比较耗时的。为了提供性能,开发连接池。
2.什么是连接池
javaee规范规定:连接池必须实现接口,javax.sql.DataSource (数据源)
为了获得连接 getConnection()
连接池给调用者提供连接,当调用者使用,此链接只能供调动者是使用,其他人不能使用。
当调用者使用完成之后,必须归还给连接池。连接必须重复使用。3.自定义连接池
4.第三方连接池
DBCP,apache
C3P0 ,hibernate 整合
tomcat 内置(JNDI)1.Apache提供的
2.导入jar包
commons-dbcp-1.4.jar 核心包
commons-pool-1.6.jar 依赖包3.核心类
public class BasicDataSource implements DataSource4.手动调用
//1 创建核心类
BasicDataSource dataSource = new BasicDataSource();
//2 配置4个基本参数
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql:///day16_db");
dataSource.setUsername("root");
dataSource.setPassword("1234");
//3 管理连接配置
dataSource.setMaxActive(30); //最大活动数
dataSource.setMaxIdle(20); //最大空闲数
dataSource.setMinIdle(10); //最小空闲数
dataSource.setInitialSize(15); //初始化个数5.配置调用
DBCP采用properties文件,key=value ,key为 BasicDataSource属性(及setter获得)
//0 读取配置文件
InputStream is = TestDBCP.class.getClassLoader().getResourceAsStream("dbcpconfig.properties");
Properties properties = new Properties();
properties.load(is);
//1 加载配置文件,获得配置信息
DataSource dataSource = BasicDataSourceFactory.createDataSource(properties);6.配置文件 dbcpconfig.properties
#连接设置
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/day16_db
username=root
password=1234
#<!-- 初始化连接 -->
initialSize=10
#最大连接数量
maxActive=50
#<!-- 最大空闲连接 -->
maxIdle=20
#<!-- 最小空闲连接 -->
minIdle=5
#<!-- 超时等待时间以毫秒为单位 6000毫秒/1000等于60秒 -->
maxWait=60000
#JDBC驱动建立连接时附带的连接属性属性的格式必须为这样:[属性名=property;]
#注意:"user" 与 "password" 两个属性会被明确地传递,因此这里不需要包含他们。
connectionProperties=useUnicode=true;characterEncoding=gbk
#指定由连接池所创建的连接的自动提交(auto-commit)状态。
defaultAutoCommit=true
#driver default 指定由连接池所创建的连接的只读(read-only)状态。
#如果没有设置该值,则“setReadOnly”方法将不被调用。(某些驱动并不支持只读模式,如:Informix)
defaultReadOnly=
#driver default 指定由连接池所创建的连接的事务级别(TransactionIsolation)。
#可用值为下列之一:(详情可见javadoc。)NONE,READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, SERIALIZABLE
defaultTransactionIsolation=READ_UNCOMMITTED1.第三方提供,非常优秀
2.导入jar包
c3p0-0.9.2-pre5.jar 核心包
mchange-commons-java-0.2.3.jar 依赖包
c3p0-oracle-thin-extras-0.9.2-pre5.jar 使用oracle的依赖3.核心类
ComboPooledDataSource4.手动调用
//1 核心类 (日志级别:debug info warn error)
ComboPooledDataSource dataSource = new ComboPooledDataSource();
//2 基本4项
dataSource.setDriverClass("com.mysql.jdbc.Driver");
dataSource.setJdbcUrl("jdbc:mysql:///day16_db");
dataSource.setUser("root");
dataSource.setPassword("1234");
//3 优化
dataSource.setMaxPoolSize(30); //最大连接池数
dataSource.setMinPoolSize(10); //最小连接池数
dataSource.setInitialPoolSize(15); //初始化连接池数
dataSource.setAcquireIncrement(5); //每一次增强个数5.配置调用
加载位置:WEB-INF/classes (classpath , src)
配置文件名称:c3p0-config.xml
//1 c3p0...jar 将自动加载配置文件。打包后从WEB-INF/classes (src)目录加载名称为c3p0-config.xml的文件
//ComboPooledDataSource dataSource = new ComboPooledDataSource(); //自动从配置文件 <default-config>
ComboPooledDataSource dataSource = new ComboPooledDataSource("itheima"); //手动指定配置文件 <named-config name="itheima"> 6.配置文件 c3p0-config.xml
<c3p0-config>
<!-- 默认配置,如果没有指定则使用这个配置 -->
<default-config>
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql:///day16_db</property>
<property name="user">root</property>
<property name="password">1234</property>
<property name="checkoutTimeout">30000</property>
<property name="idleConnectionTestPeriod">30</property>
<property name="initialPoolSize">10</property>
<property name="maxIdleTime">30</property>
<property name="maxPoolSize">100</property>
<property name="minPoolSize">10</property>
<property name="maxStatements">200</property>
<user-overrides user="test-user">
<property name="maxPoolSize">10</property>
<property name="minPoolSize">1</property>
<property name="maxStatements">0</property>
</user-overrides>
</default-config>
<!-- 命名的配置 -->
<named-config name="itheima">
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql:///day16_db</property>
<property name="user">root</property>
<property name="password">1234</property>
<!-- 如果池中数据连接不够时一次增长多少个 -->
<property name="acquireIncrement">5</property>
<property name="initialPoolSize">20</property>
<property name="minPoolSize">10</property>
<property name="maxPoolSize">40</property>
<property name="maxStatements">0</property>
<property name="maxStatementsPerConnection">5</property>
</named-config>
</c3p0-config> 配置:
1.给tomcat配置数据源(连接池),使用
方式1:%tomcat%/conf/server.xml --> 在<Host>标签下添加<Context>
方式2:%tomcat%/conf/Catalina/localhost/day16.xml ---> <Context>
day16/META-INF/Context.xml 在项目的META-INF下创建Context.xml,会自动发布到“方法2”指定位置
Context.xml中的内容:
<Context>
<!--
name 存放进去名称
auth 存放位置
type 确定存放内容,tomcat将通过指定接口创建实例,底层使用DBCP
其他都是DBCP属性设置
-->
<Resource name="jdbc/itheima" auth="Container" type="javax.sql.DataSource"
maxActive="100" maxIdle="30" maxWait="10000"
username="root" password="1234" driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/day16_db"/>
</Context>2 从JNDI容器获取,在当前项目web.xml配置
<!-- 给当前项目配置,从JNDI容器获得指定名称内容 -->
<resource-ref>
<res-ref-name>jdbc/itheima</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>3.使用
//0 包名:javax.naming
//1 初始化JNDI容器
Context context = new InitialContext();
//2 获得数据源 固定 “java:/comp/env”
DataSource dataSource = (DataSource)context.lookup("java:/comp/env/jdbc/itheima");public class FirstJDBC {
public static void main(String[] args) throws Exception {
// 0.准备变量
String driver = "com.mysql.jdbc.Driver";// mysql驱动实现类
String url = "jdbc:mysql://localhost:3306/day15_db";// 确定数据库服务器地址,端口号,使用数据库
String user = "root";// 登录名称
String password = "1234";// 登录密码
// 1.注册驱动
Class.forName(driver);
// 2.获得链接
Connection conn = DriverManager.getConnection(url, user, password);
// 3.获得语句执行者
Statement st = conn.createStatement();
// 4.发送sql语句,查询 结果相当于一个set集合,每一个成员表示数据库表中一条记录
ResultSet rs = st.executeQuery("select * from t_user ");
// 5.处理结果
rs.next();// 移动到第一行
// getXxx获取某一行的指定列或字段值 getXxx(int 列数),getXxx(String 字段名)
int id = rs.getInt("id");
String username = rs.getString("username");
String userPassword = rs.getString("password");
System.out.printf("id:"+id+" username:"+username+" password:"+password);
// 6.释放资源,优先关闭最后使用的
rs.close();
st.close();
conn.close();
}
}1.需要导入两个jar包junit.jarhamcrest-core.jar
放入libs目录下即可
2.类名alt+enter,然后选择需要添加测试的方法即可
测试用例方法,公共 没有返回值 非静态 方法名自定义 没有参数列表
方法名建议:test方法名()
public class DemoTest {
private Demo demo;
@Before //测试方法执行前
public void myBefore(){
System.out.println("之前");
demo = new Demo();
//初始化数据
}
@After //测试方法执行后
public void myAfter(){
System.out.println("之后");
//方法资源
}
@Test(timeout=1000) //timeout 设置测试时间,如果超时性能有问题
public void testAdd() {
try {
Thread.sleep(2000);
} catch (Exception e) {
}
int sum = demo.add(1, 2);
//断言
Assert.assertEquals(3, sum);
assertEquals(3, sum); //使用静态导入的结果
}
@Test
public void testMul() {
int sum = demo.mul(1, 2);
}
@BeforeClass
public static void myBeforeClass(){
System.out.println("类之前");
}
@AfterClass
public static void myAfterClass(){
System.out.println("类之后");
}
}public class JdbcUtils {
private static String url;
private static String user;
private static String password;
// 这些配置文件的东西只用加载一次就可以了,写在静态代码块中
static {
try {
// 参数配置应该放在配置文件中
// 1. 加载properties文件
// 方式1:使用ClassLoader加载资源
//InputStream is = JdbcUtils.class.getClassLoader().getResourceAsStream("jdbcInfo.properties");
// 方式2:使用Class对象加载,必须加上/,表示src
InputStream is = JdbcUtils.class.getResourceAsStream("/jdbcInfo.properties");
// 2. 解析配置文件
Properties properties = new Properties();
properties.load(is);
// 3. 获得配置文件中的数据
String driver = properties.getProperty("driver");
url = properties.getProperty("url");
user = properties.getProperty("user");
password = properties.getProperty("password");
// 4. 注册驱动
Class.forName(driver);
} catch (Exception e){
throw new RuntimeException(e);
}
}
/**
* 获得连接
*/
public static Connection getConnection(){
try {
Connection conn = DriverManager.getConnection(url, user, password);
return conn;
} catch (Exception e){
// 将编译时异常转换成运行时异常,开发中常见运行时异常
// throw new RuntimeException(e);
// 此处可以使用自定义异常
// 类与类之间进行数据交换时可以使用return返回数据.
// 也可以使用自定义异常返回值,调用者try{} catch(e){ e.getMessage() 获得需要的数据}
throw new MyConnectionException(e);
}
}
/**
* 释放资源
*/
public static void closeResource(Connection conn, Statement st, ResultSet rs){
try {
if (rs != null) {
rs.close();
}
} catch (Exception e){
throw new RuntimeException(e);
} finally {
try {
if (st != null) {
st.close();
}
} catch (Exception e){
throw new RuntimeException(e);
} finally {
try {
if (conn != null) {
conn.close();
}
} catch (Exception e){
throw new RuntimeException(e);
}
}
}
}
}继承RuntimeException 覆写方法
将编译时异常转换成运行时异常,开发中常见运行时异常
throw new RuntimeException(e);
类与类之间进行数据交换时可以使用return返回数据.
也可以使用自定义异常返回值,调用者try{} catch(e){ e.getMessage() 获得需要的数据}
public void demo1(){
Connection conn = null;
Statement st = null;
ResultSet rs = null;
try {
conn = JdbcUtils.getConnection();
// ....
} catch (Exception e){
throw new RuntimeException(e);
} finally {
// 释放资源
JdbcUtils.closeResource(conn,st,rs);
}
}1.0 所有的驱动实现类必须实现规范接口,java.sql.Driver接口
1.1 原始编写方式:DriverManager.registerDriver(new Driver());
特点:必须导包 import com.mysql.jdbc.Driver;
硬编程,内容写死的,无法扩展,不易于数据变迁(更换)
源码:public class com.mysql.jdbc.Driver implements java.sql.Driver
1.2 建议编写方式:Class.forName("com.mysql.jdbc.Driver");
特点:指定类如果有static{} 里面的内容将自动执行。
源码:
static {
try {
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
mysql Driver实现类,将自己进行注册。
优点:使用字符串方法加载到内容(注册),之后可以将驱动配置到配置文件中,之后只需要修改配置文件,数据库就更改。
1.3 此行代码可省略,建议不要省略。
mysql驱动 高版本,将自动加载驱动并注册。
文件:mysql-connector-java-5.1.22-bin.jar/META-INF/services/java.sql.Driver
内容:com.mysql.jdbc.Driver
1.4 错误总结
* ClassNotFoundException ,是否导入jar包?驱动名称是否正确?
* java.lang.NoClassDefFoundError 如果配置文件放置位置错误就会报这个异常
1.5 mysql com.mysql.jdbc.Driver 子类 org.gjt.mm.mysql.Driver
源码:public class Driver extends com.mysql.jdbc.Driver2.1 介绍
使用连接接口:java.sql.Connection,只有获得连接才可以操作数据库。
通过DriverManager 驱动管理者类获得连接。getConnection(url,user,password)
2.2 url 确定访问数据库位置
格式# 协议:子协议:子名称
协议 固定值 --> jdbc
子协议 --> 确定数据,例如:mysql、oracle 等
子名称 --> localhost主机,3306端口,day15_db数据库名称
参数 --> jdbc:mysql://localhost:3306/day15_db?useUnicode=true&characterEncoding=UTF-8
设置请求编码,安装如果指定UTF-8,不需要设置的。如果安装时设置的编码为ISO8859-1编码,中文乱码需要如上处理。
主机默认localhost,端口默认3306
简写方式 --> jdbc:mysql:///day15_db
2.3 错误总结
* Unknown database 'day15_db2' , 表示数据库不存在。
* Access denied for user 'root'@'localhost' (using password: YES) , 账号和密码不匹配3.1 操作对象
* Statement , 语句执行者,获得方式 conn.createStatement()【】
* PreparedStatement , 预处理对象,获得方法 conn.prepareStatement(sql)【】
* 必须先提供sql语句,进行预先处理。
* CallableStatement 存储过程, prepareCall(String sql),将sql语句编写数据库,相当于数据库函数,执行时 只需要传递实际参数
3.2 Statement
int executeUpdate(sql) 执行DDL/DML语句,返回影响的行数。【】
ResultSet executeQuery(sql) 执行DQL语句,返回结果集(相当于一个表)【】
boolean execute(sql)
返回值true,表示执行DQL语句,必须通过 getResultSet() 获得结果集
返回值false,表示执行DML/DDL语句,必须通过 getUpdateCount() 获得影响行数
3.3 滚动结果集 (了解)
* jdbc规范 默认结果集forward ,只能向前的结果集。
* 滚动结果集:可以向前,也可以向后。mysql 直接支持滚动
* ResultSet api
next() 下一个(向前)
previous() 上一个(向后)
* 结果集ResultSet要滚动,前提Statement必须设置支持的。
* 使用方法:createStatement(int resultSetType, int resultSetConcurrency)
resultSetType - 结果集类型,
ResultSet.TYPE_FORWARD_ONLY,仅仅只能向前
ResultSet.TYPE_SCROLL_INSENSITIVE,可以滚动,不敏感。滚动中,数据库发生改变,结果集内容不改变的。
数据库的数据是否同步到结果集ResultSet中。
ResultSet.TYPE_SCROLL_SENSITIVE,可以滚动,敏感。滚动中,数据库数据发生改变,结果集内容改变。
resultSetConcurrency - 并发类型
ResultSet.CONCUR_READ_ONLY ,结果集只能读,不能改。
ResultSet.CONCUR_UPDATABLE,结果集可以更新,数据一并更改。
结果集数据同步到数据库
* 操作
获得 getXxx(int)获得指定列号的内容, getXxx(String)获得指定列名(字段)的内容
例如:getString(4) 获得第4列, getString("username") 获得字段名称username的值sql注入 :用户输入实际参数,作为了sql语句语法的一部分,数据库编译在执行时生效的。
select * from t_user where username = ‘jack’ or 1=1 or 1=’’ and password = ‘12345’
select * from t_user where username = ‘jack’ –’ and password = ‘12345’
解决方案:
1. 手动方式:\转义单引号
2. 使用预处理对象,防止sql注入
1) 先提供sql语句,将实际参数使用占位符?替换。
例如:select * from t_user where username = ? and password = ?
2) 获得预处理对象,获得对象时必须提供sql语句,让sql语句预先进行编译。
3) 设置实际参数
PreparedStatement 提供 setXxx(int , Object)
参数1:int表示 ?位置,从1开始。
参数2:Object具体类型,如果字符串String等。
3. PreparedStatement 接口 是 Statement接口的子接口。
但是execute(sql) 父类方法,子类使用抛异常。使用的没有参数。
特点:
sql 易于编写,更佳清晰
提高性能,编译一次,可以执行多次。
编写步骤:
1.提供sql语句,并将实际参数使用?占位符
2.获得预处理对象,注意提供sql语句
3.设置实际参数,将?替换回来
4.执行,注意:不能设置sql语句。
Statement 和 PreparedStatement 对比:
一般情况使用PreparedStatement,之后学习框架DbUtils底层使用PreparedStatement,hibernate底层使用也是。
如果使用Statement,必须保证sql都是自己编写,实际参数都是自己传递的。
PreparedStatement 应用场景
1.防sql注入
2.大数据
大数据类型:blob 字节 、text 字符
3.批处理分类:
设置数据库存放目录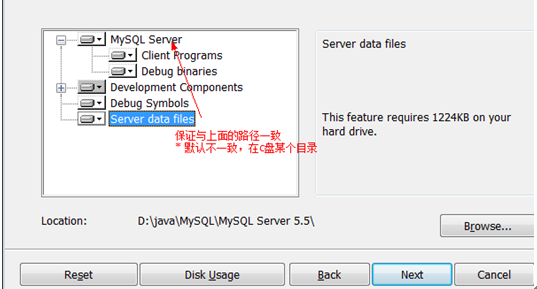
选择配置类型 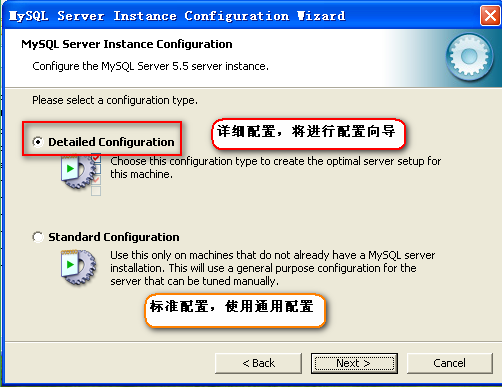
选择服务类型 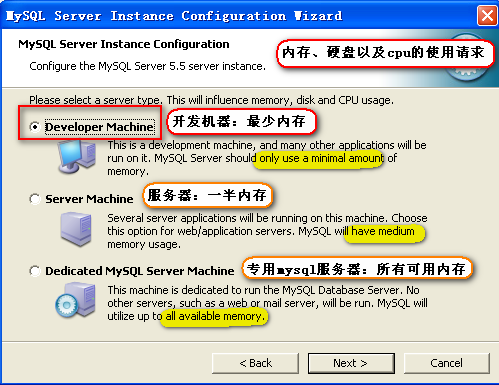
选择数据库类型 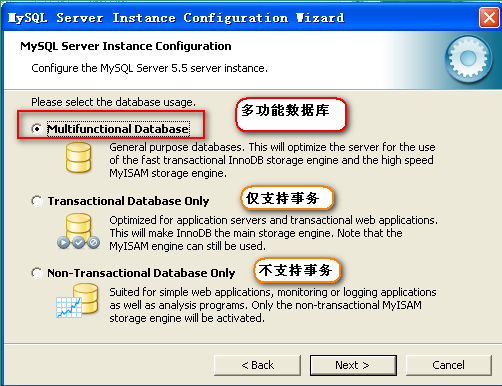
设置并发连接数 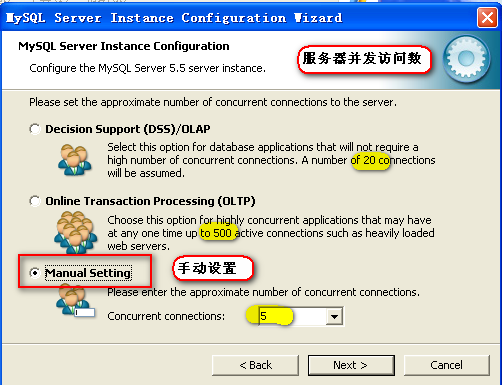
配置网络参数 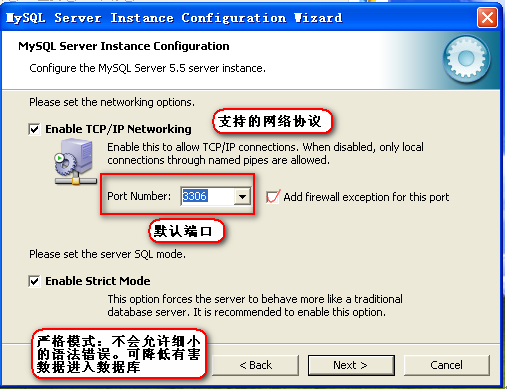
设置字符集 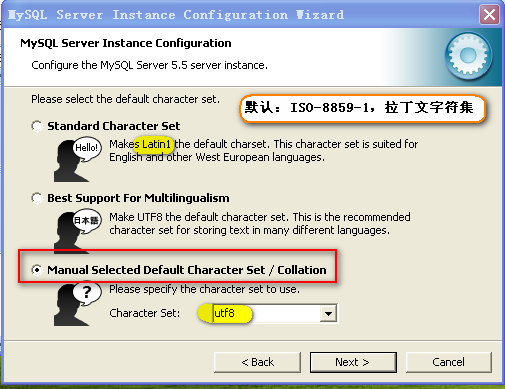
设置服务和环境静变量 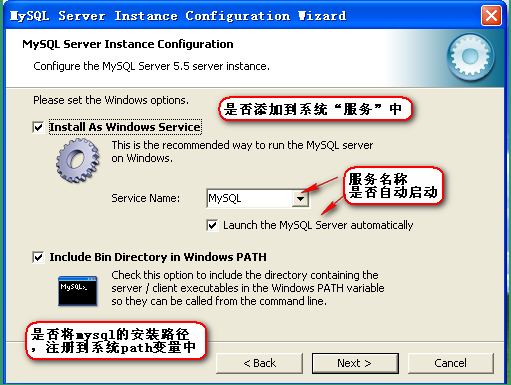
设置数据库密码 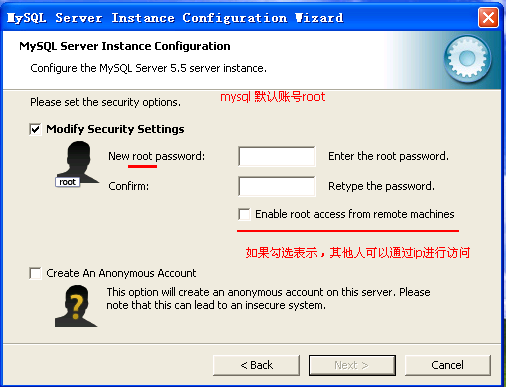
测试
C:\Users\xxxxx>mysql --version
mysql Ver 14.14 Distrib 5.5.27, for Win64 (x86)mysql -h 主机(ip地址) -u 账号 -p 密码
use mysql;
update user set password=password('1234') where user='root';show databases;use 数据库名;show tables;select database();status;desc 表名;show character set;show create table 表名;> 操作数据库或表结构create database 数据库名称;show create database 数据库名称;drop database [if exists] 数据库名称;alter database 数据库名 character set 字符集 collate 比较方式不建议修改。> 操作表之前,必须先切换数据库.创建表 : create table 表名(字段描述,字段描述,...);
create table users(
id varchar(32),
name varchar(50),
age int
);删除表 : drop table 表名;
修改字段类型 : alter table 表名 modify 字段名称 新类型;
修改字段名称 : alter table 表名 change 旧字段 新字段 新字段类型;
添加字段 : alter table 表名 add column 字段名称 字段类型;
删除字段 : alter table 表名 drop column 字段名称;
重命名表名 : alter table 表名 rename [to] 新表明;
字符串
char(n) 固定字符串,例如:char(5) 表示可以存放5个字符,且必须是5个。
如果插入 “abc”,结果“abc ” 右边自动添加空格。
varchar(n) 可变长字符串,例如:varchar(5),表示最多存放5个字符,如果不够就原样存放。
如果插入“abc”,结果“abc”数字
bit 比特
tinyint byte
mediumint short
int int 【】
bigint long
float float
double(m,d) double 【】 --m数字长度,d精度及小数位
numeric Number 所有数字
例如:double(5,2) 5表示整个数字为5位,2表示小数位2个。最大值。999.99时间日期
** 之后使用java日期时间类型:java.util.Date 。如果要使用java.sql..类型,只能存放dao层
date 日期 java.sql.Date
datetime 日期时间 ---
time 时间 java.sql.Time
timestamp 时间戳 java.sql.Timestamp
sql转util : java.util.Date date = new java.sql.Date(long);
util转sql : new java.sql.Date( new java.util.Date().getTime() )大数据
字节:存放二进制 (java.sql.Blob :Binary Large Object 二进制大对象)
TINYBLOB 255
blob 64k
longblob 4G
字符:存放文本 (java.sql.Clob :Character Large Object 字符大对象)
TINYTEXT 255
text 64k
longtext 4G> 对表中的数据进行增删改的操作insert into 表名(字段列表) values(字段对应值);注意:
多个字段之间使用逗号分隔
字段值必须使用引号(建议单引号),如果是整形数据引号可以省略
字段默认值为nullupdate 表名 set 字段名=字段值,字段名=字段值,...;
update 表名 set 字段名=字段值,字段名=字段值,...where 条件;delete from 表名 [where 条件];注意:
delete from users; 删除表中的所有数据.进行删除操作留心,一般情况应用系统不进行数据删除,提供一个标记字段,逻辑删除(0表示已删除,1表示没有删除).给字段添加规则,约定内容编写。最终作用保证数据的完整性,一致性等。
关键字:primary key
要求:数据唯一,不能为null.1.定义表:声明字段时,定义主键.(primary key)只能修饰一个字段.
create table pk01(
id varchar(32) primary key ,
content varchar(50)
);
2.定义表,声明字段之后,在约束区域定义主键。—特点 constraint primary key (字段1,字段2,….) 可以设置多个字段
create table pk02(
id varchar(32),
content varchar(50),
constraint primary key (id)
);
3.定义表,声明字段,表创建之后。修改表结构添加约束。–特点:也可以设置多个字段,更灵活。
create table pk03(
id varchar(32),
content varchar(50)
);
alter table pk03 add constraint primary key (id);
关键字:unique
要求:被修饰的字段不能重复1.定义表,声明字段时,定义唯一约束。— 特点:unique只能修饰一个字段
create table un01(
id varchar(32),
content varchar(50) unique
);
2.定义表,声明字段之后,在约束区域定义唯一约束。—特点 constraintunique (字段1,字段2,….) 可以设置多个字段
create table un02(
id varchar(32),
content varchar(50),
constraint unique (content)
);
3.定义表,声明字段,表创建之后。修改表结构添加唯一约束。–特点:也可以设置多个字段,更灵活。
create table un03(
id varchar(32),
content varchar(50)
);
alter table un03 add constraint unique (content);
关键字:not null
要求:被修饰的字段不能为null1.定义表,声明字段时,添加约束。
create table nn01(
id varchar(32),
content varchar(50) not null
);
create table nn02(
id varchar(32),
content varchar(50) not null default ‘dzd’
);
总结: 主键 = 唯一 + 非空
定义:
关键字:auto_increment
mysql特有的一个特殊的关键字,被修饰的字段将自动的累加(oracle没有,但提供徐磊sequence)
注意:
1.字段类型必须是整型,一般使用int
2.必须是key(主键/唯一),一般使用主键primary key
3.被auto_increment修饰的字段,不需要手动维护数据,mysql将自动维护
代码示例:
create table ai01(
id varchar(32) auto_increment, # 错误代码 不能用于字符串
content varchar(50)
);
create table ai02(
id int auto_increment, # 错误代码 必须是primary key
content varchar(50)
);
create table ai03(
id int primary key auto_increment, # 正确代码
content varchar(50)
);
面试题:
drop table ai03; #删除表,数据和表都不存在了。
delete from ai03; #删除所有数据,表仍然存在。表中计数器没有重置。
truncate table ai03; #清空所有数据,表中的计数器将重置归0。
delete 和 truncate 对比
delete 将数据删除了
truncate 先删除了表,再创建表。
关键字:foreign key删除主键:mysql> `alter table 表名 drop primary key;`
删除唯一:修改列
删除外键:mysql> `alter table 表名 drop foreign key 名称;`set names gbk;查询所有:
select * from users;
select id,name,age from user;查询部分字段:
select id,name from user;合并查询条件:
select id,concat(firstname,secondname),age from users;字段别名:
select id,concat(firstname,secondname) as `姓名`,age from users;特殊字符或者关键字使用重音符 ``
查询分数等于60的:
select * from users where count='60';查询年龄大于18的学生:
select * from users where age > 18;查询分数在60-80之间:
select * from users where count >= 60 and count <= 80;
select * from users where count between 60 and 80;查询年龄是18或20的学生:
select * from users where age = 18 or age = 20;模糊查询,不完全匹配:
字段:like
符号:
%匹配多个数据
'云' 只能匹配一个云
'%云' 匹配以云结尾的
'云%' 匹配以云开头的
'%云%' 包含云
_匹配一个数据查询分数等于60 或者 分数大于90并且年龄大于23
select * from users where count = 60 or count > 90 and age > 23;
select * from users where count = 60 or (count > 90 and age > 23);
### 运算符优先级 and 优先 or查询没有考试的学生
select * from users where count is null;查询所有考试的学生
select * from users where count is not null;运算符 不相等 != <>
聚合函数:对表中的数据进行统计,显示一个数据(一行一列的数据)
聚合函数不统计 null值。有多少条记录 count(* | 字段)
select count(*) from users;
select count(id) from users; #7
select count(count) from users; #6平均成绩 avg
select avg(count) from users; #不精准(没有null)
select sum(count)/count(id) from users; #精准(计算null)最高成绩 max
select max(count) from users;最小年龄 min
select min(age) from users;班级总成绩 sum
select sum(count) from users;查询所有的年龄数(排序)
去重复 distinct
排序 select..... order by 字段1 关键字, 字段2 关键字,....
### 关键字 asc 升序 , desc 降序
select distinct age from users order by age desc; # age asc 等效 age [asc] 添加班级字段(classes)
alter table users add column classes varchar(3);
update users set classes = 1;
update users set classes = 2 where id='u005' or id ='u006' or id ='u007';
update users set classes = 2 where id in ('u005','u006','u007');查询1班和2班的平均成绩
分组 select ... group by 分组字段;
select classes,avg(count) from users group by classes;
select classes,sum(count)/count(id) from users group by classes;查询班级,平均成绩不及格的,班级成员信息
(查询2班,成员信息)
select * from users where classes = 2;select * from A,B where A.classes = B.classes and avg < 60;
select ... from 表名 [as] 别名select * from users,(
select classes,sum(count)/count(id) as cavg from users group by classes) as B
where users.classes = B.classes and cavg < 60;
#查询结果一行一列,可以使用
select id,(xxx) from
select ... from ... where id= (xxxx)
#查询结果一行多列(查询多个值),使用关键字 in ,all 等
#查询结果多行多列,可以当另一个表使用一种软件设计模式,B/S架构都支持。例如:java、.net、php等
思想:业务逻辑处理与数据显示相分离。
Model:模型,用于封装数据
View:视图,用于显示数据
Controller:控制器,用于控制正常执行。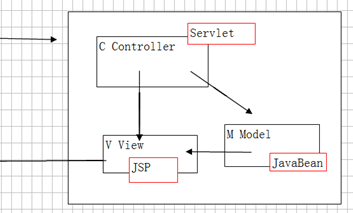
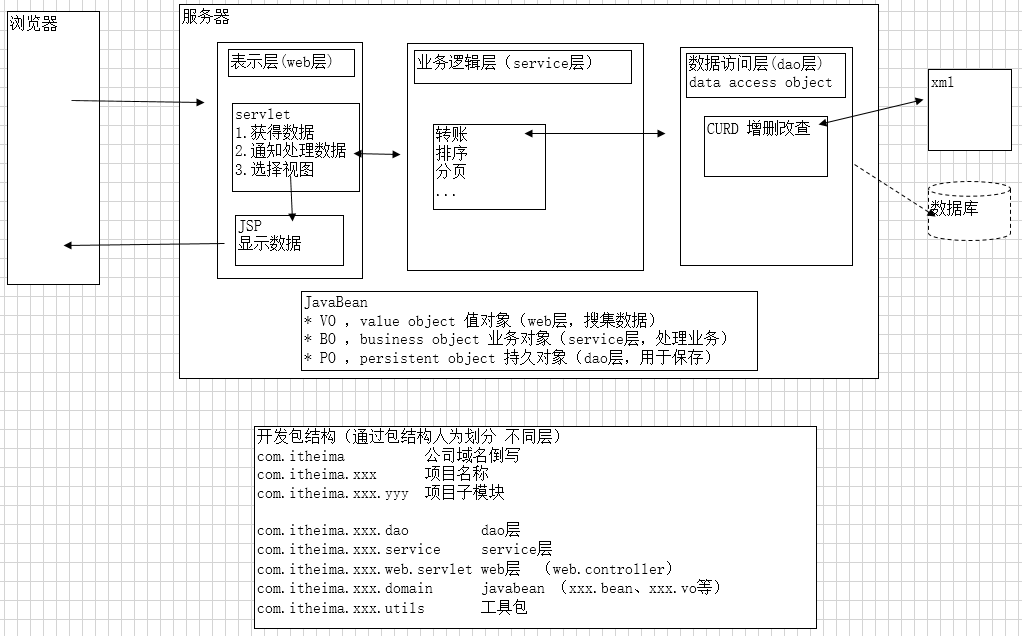
解析xml需要
com.lujiahao.web.servlet web层
com.lujiahao.service service层
com.lujiahao.dao dao层
com.lujiahao.domain javabean
com.lujiahao.utils 工具包暂定使用xml
xml内容:
<?xml version="1.0" encoding="UTF-8"?>
<users>
<user id="u001">
<username>jack</username>
<password>1234</password>
<gender>男</gender>
<age>18</age>
</user>
</users>数据库定义完成之后就开始编写JavaBean
随便写点数据的增删改查功能
一般都是写在和servlet同级的包里面
这种类型的bean里面所有的字段都是字符串
用于获得浏览器发送的数据,并对数据的有效性进行校验
具体代码实现:
public class UserFormBean {
private String id;
private String username;
private String password;
private String repassword;
private String gender;
private String age;// 因为服务器传过来的数据都是string类型的
public UserFormBean() {}
public UserFormBean(String id, String username, String password, String repassword, String gender, String age) {
this.id = id;
this.username = username;
this.password = password;
this.repassword = repassword;
this.gender = gender;
this.age = age;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String getRepassword() {
return repassword;
}
public void setRepassword(String repassword) {
this.repassword = repassword;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
// 记录错误信息 key:对应字段 value:提示信息
private Map<String,String> errorMsg = new HashMap<>();
/**
* 校验方法
*/
public boolean validate() {
boolean temp = true;
// 用户名不能为空
if (username == null || "".equals(username)) {
errorMsg.put("usernameMsg","用户名不能为空");
temp = false;
}
if (password == null || "".equals(password)) {
errorMsg.put("passwordMsg","密码不能为空");
temp = false;
} else if (! password.equals(repassword)){
errorMsg.put("repasswordMsg","确认密码和密码不一致");
temp = false;
}
return temp;
}
public Map<String, String> getErrorMsg() {
return errorMsg;
}
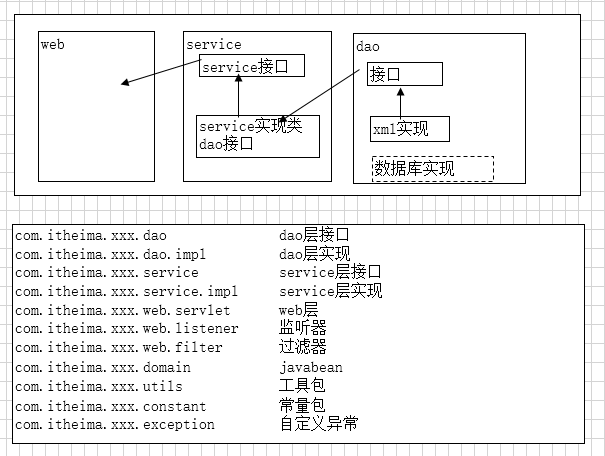
}三层结构每一层都应该是有接口和具体的实现类
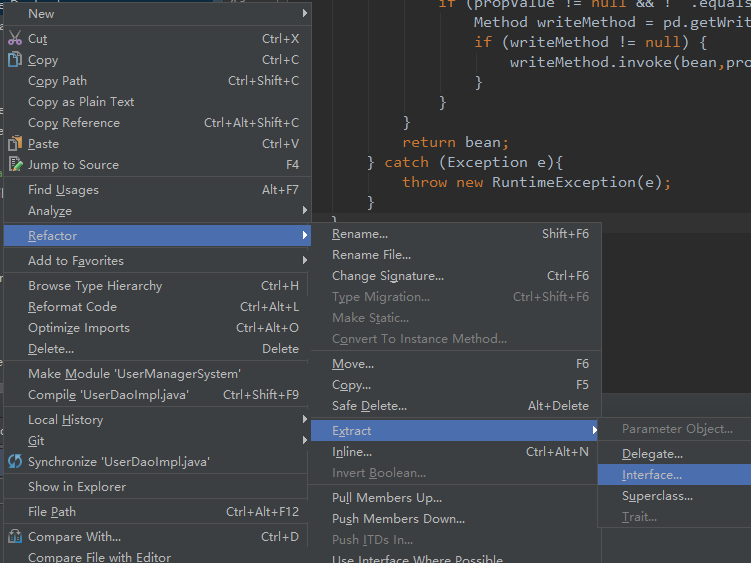
使用Intellj重构代码
通过封装的类来简化参数的自动封装
使用了反射和内省
初始代码:
// 1.获取请求参数
String id = request.getParameter("id");
String username = request.getParameter("username");
String password = request.getParameter("password");
String repassword = request.getParameter("repassword");
String gender = request.getParameter("gender");
String age = request.getParameter("age");
/**
* 数据校验
*/
UserFormBean userFormBean = new UserFormBean(id,username,password,repassword,gender,age);封装后的代码:
UserFormBean userFormBean = MyBeanUtils.populate(UserFormBean.class,request.getParameterMap());BeanUtils详细代码:
public class MyBeanUtils {
/**
* 创建JavaBean实例,并自动将对应的参数进行封装
* @param beanClass
* @param parameterMap
* @param <T>
* @return
*/
public static <T> T populate(Class<T> beanClass, Map<String,String[]> parameterMap){
try {
// 1.使用反射创建javabean实例
T bean = beanClass.newInstance();
// 2.获得javabean属性(property username-->setUsername()-->执行set方法,数据来自map
// 2.1获得所有属性--使用内省(java.beans.Introspector):jdk提供工具类,用于操作javabean
// BeanInfo jdk提供用于对javabean进行描述(封装)对象
BeanInfo beanInfo = Introspector.getBeanInfo(beanClass, Object.class);
// 2.2 获得所有的属性描述对象
PropertyDescriptor[] allPd = beanInfo.getPropertyDescriptors();
for (PropertyDescriptor pd : allPd) {
// 2.3 获得属性名称
String propName = pd.getName();
// 2.4 获得表单中对应的数据
String[] allValue = parameterMap.get(propName);
if (allValue == null) {
continue;// 当没有值的时候就跳过这个字段
}
String propValue = allValue[0];
// 2.5 如果有值,将执行set方法
if (propValue != null && !"".equals(propValue)) {
Method writeMethod = pd.getWriteMethod();// 相当于set方法 getReadMethod--相当于get方法
if (writeMethod != null) {
writeMethod.invoke(bean,propValue);
}
}
}
return bean;
} catch (Exception e){
throw new RuntimeException(e);
}
}
}