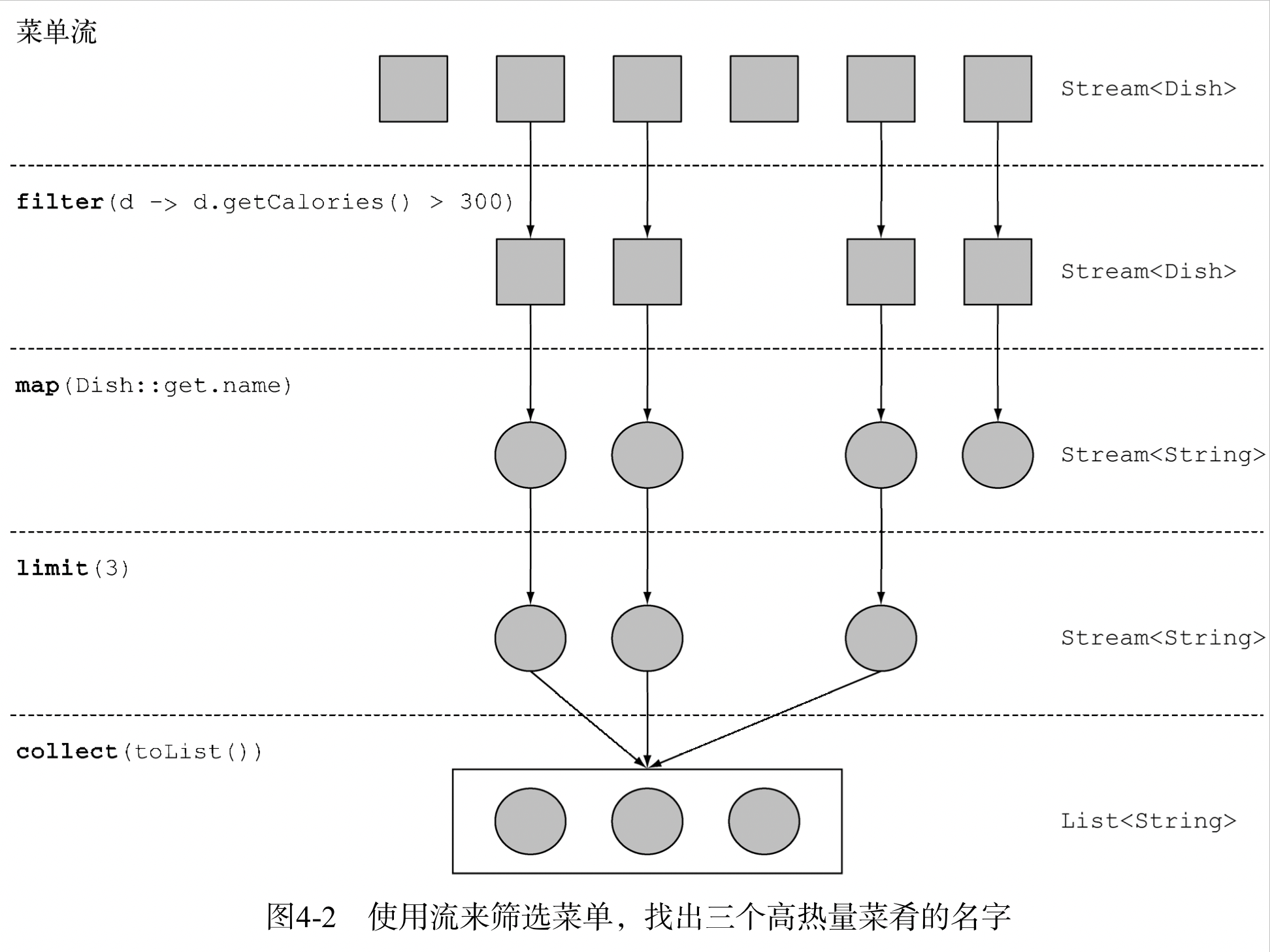
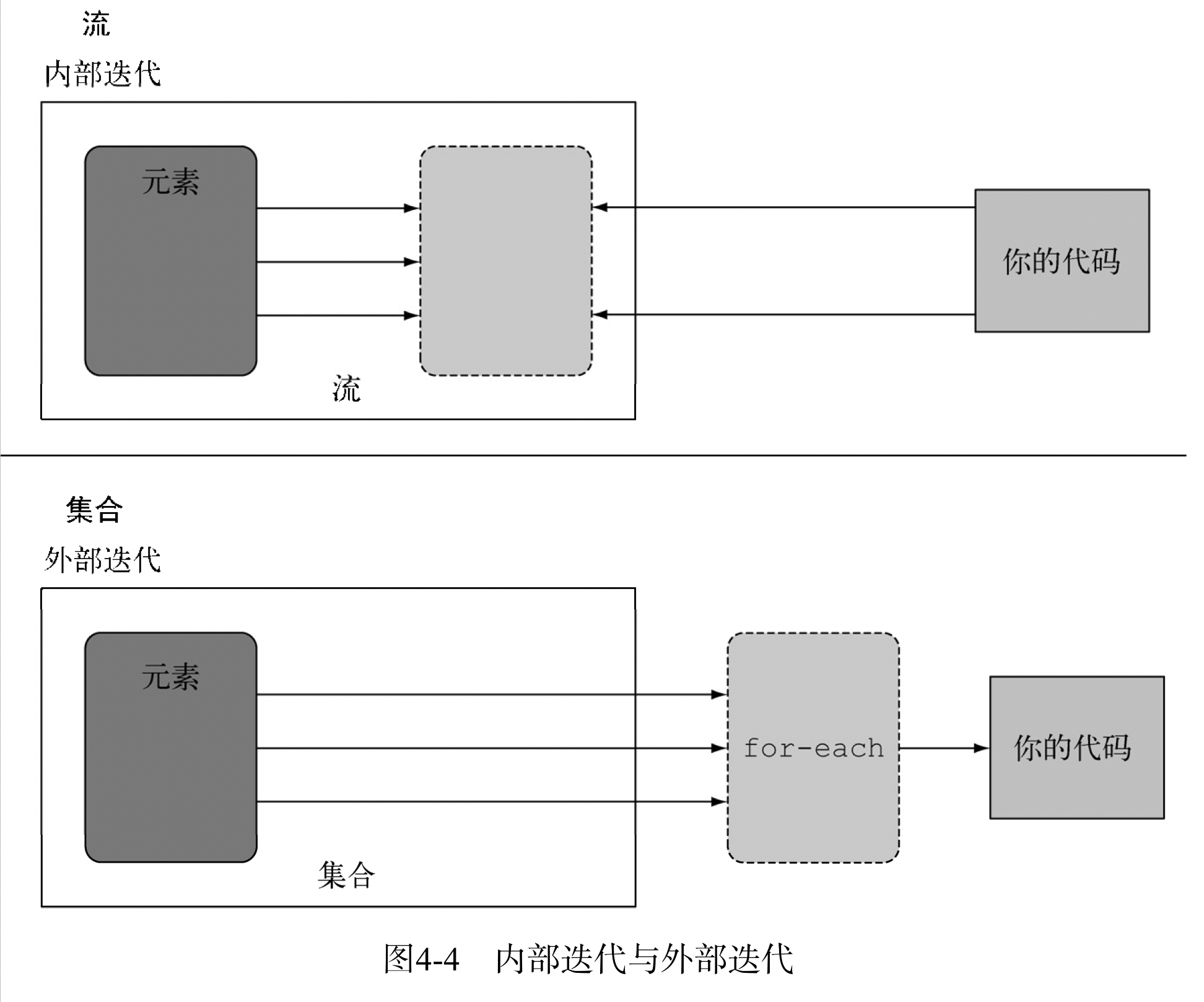
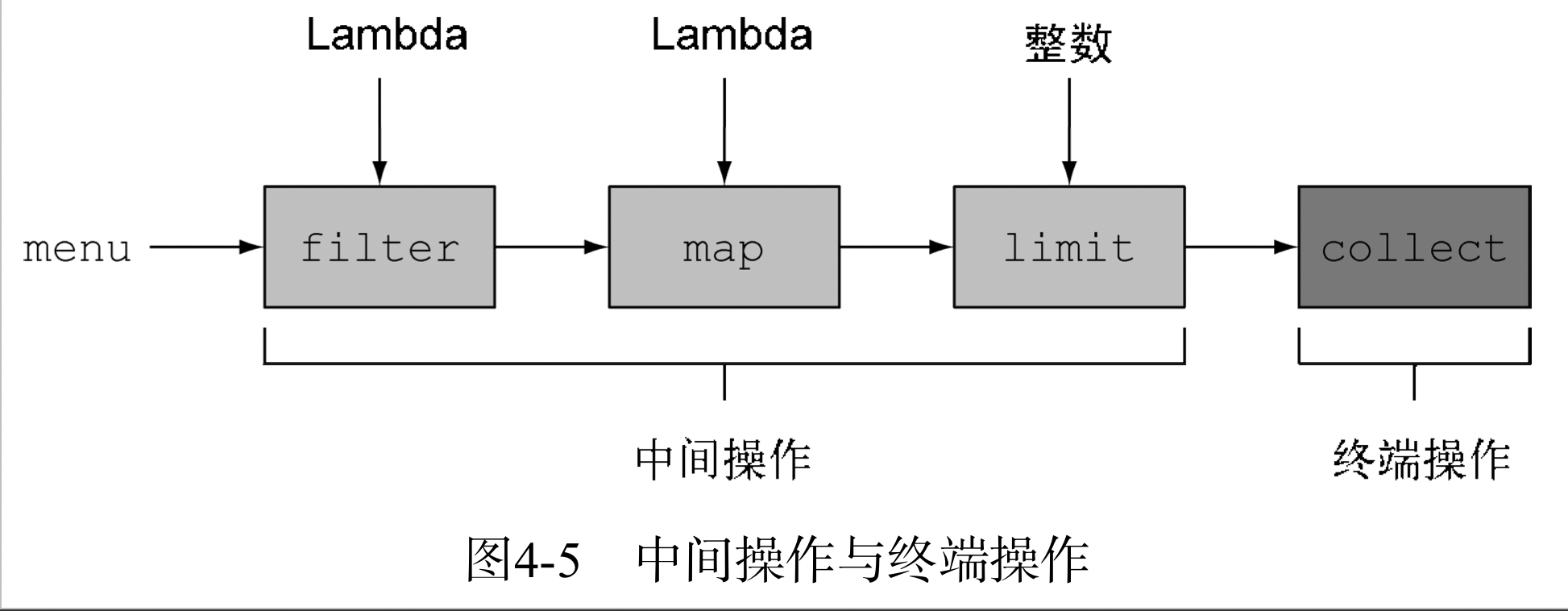
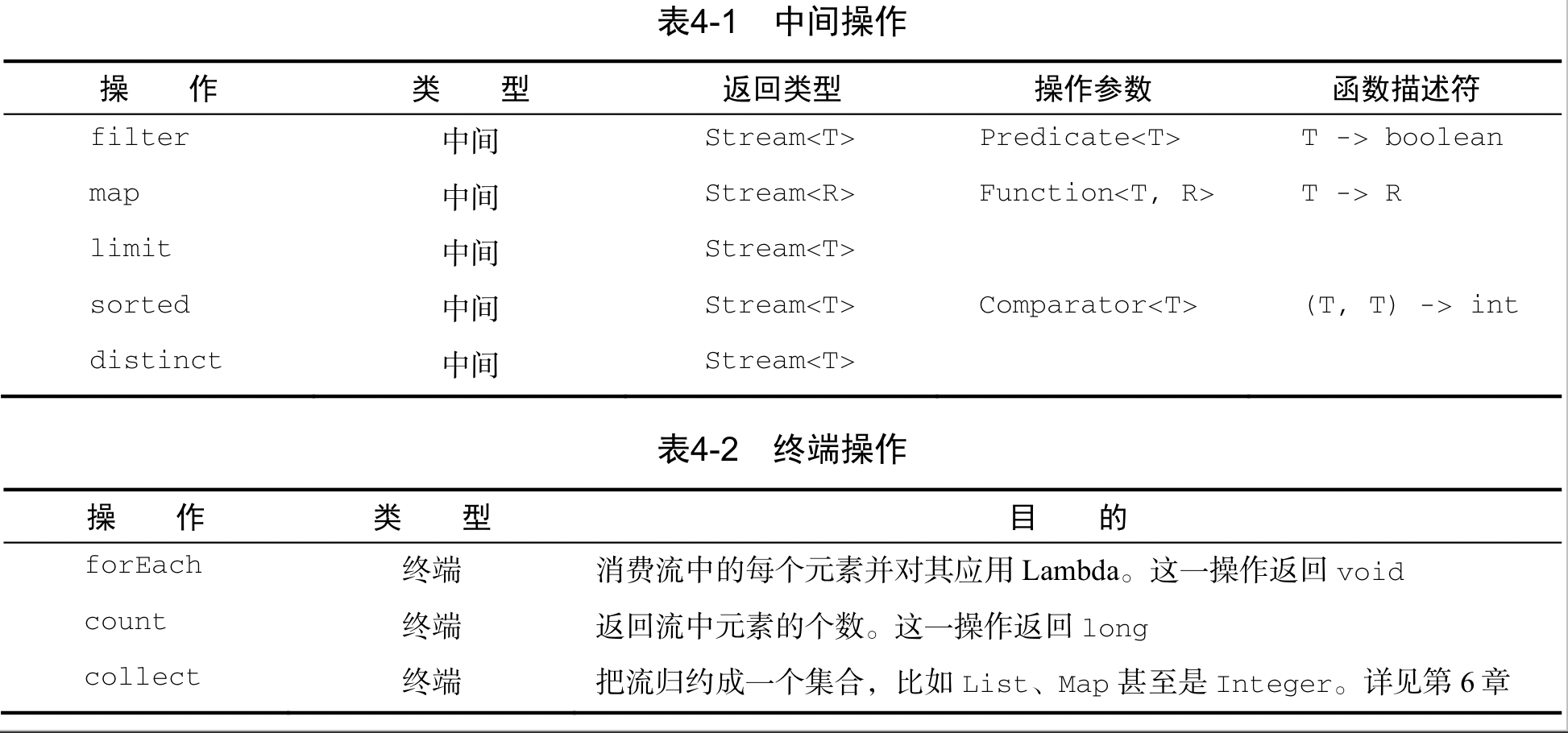
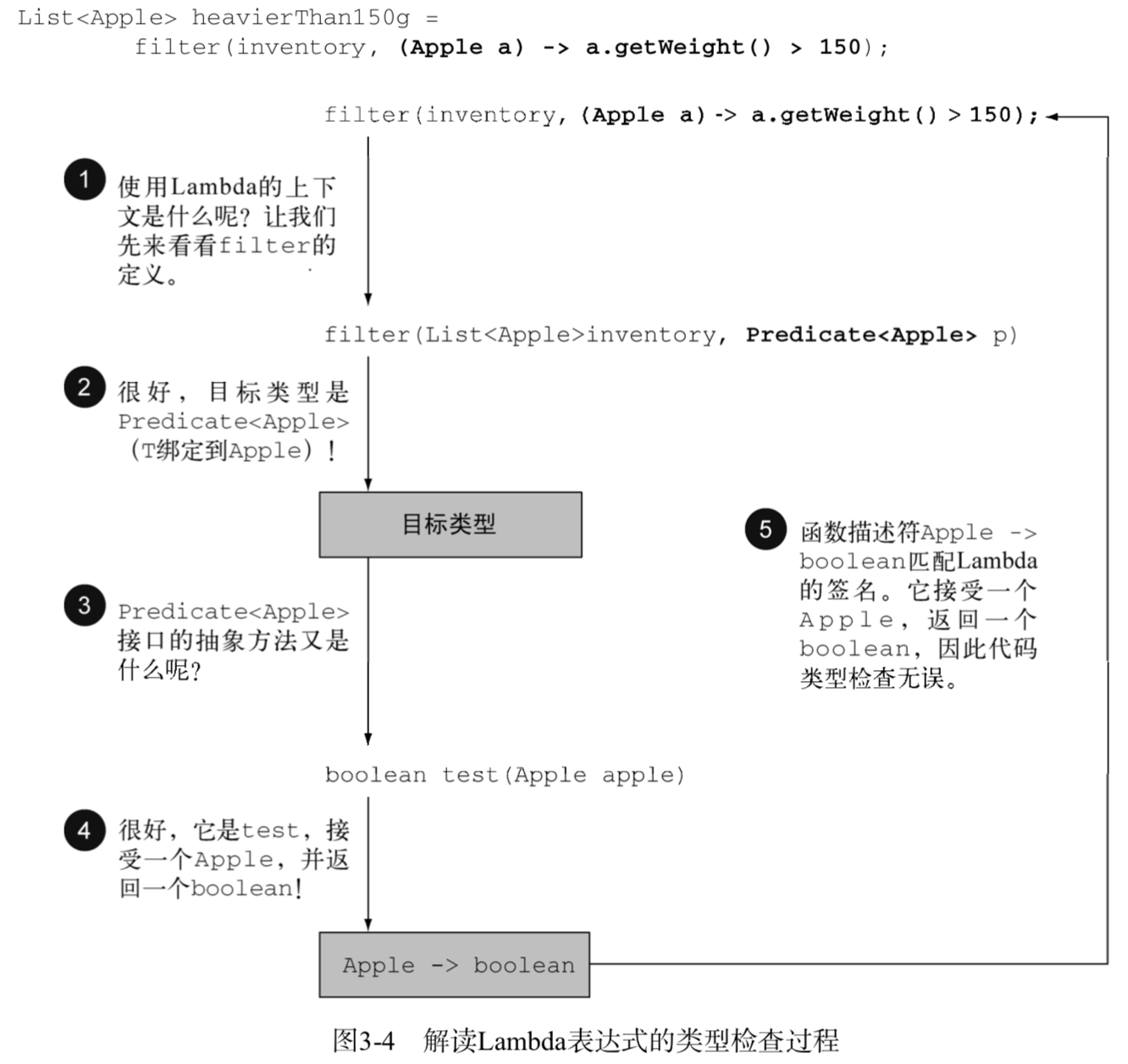
List<String> title = Arrays.asList(“Java8”,”In”, “Action”); Stream<String> s = title.stream(); s.forEach(System.out::println); s.forEach(System.out::println);
Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed at java.util.stream.AbstractPipeline.sourceStageSpliterator(AbstractPipeline.java:279) at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:580) at com.lujiahao.learnjava8.chapter4.StreamAndCollection.main(StreamAndCollection.java:16)
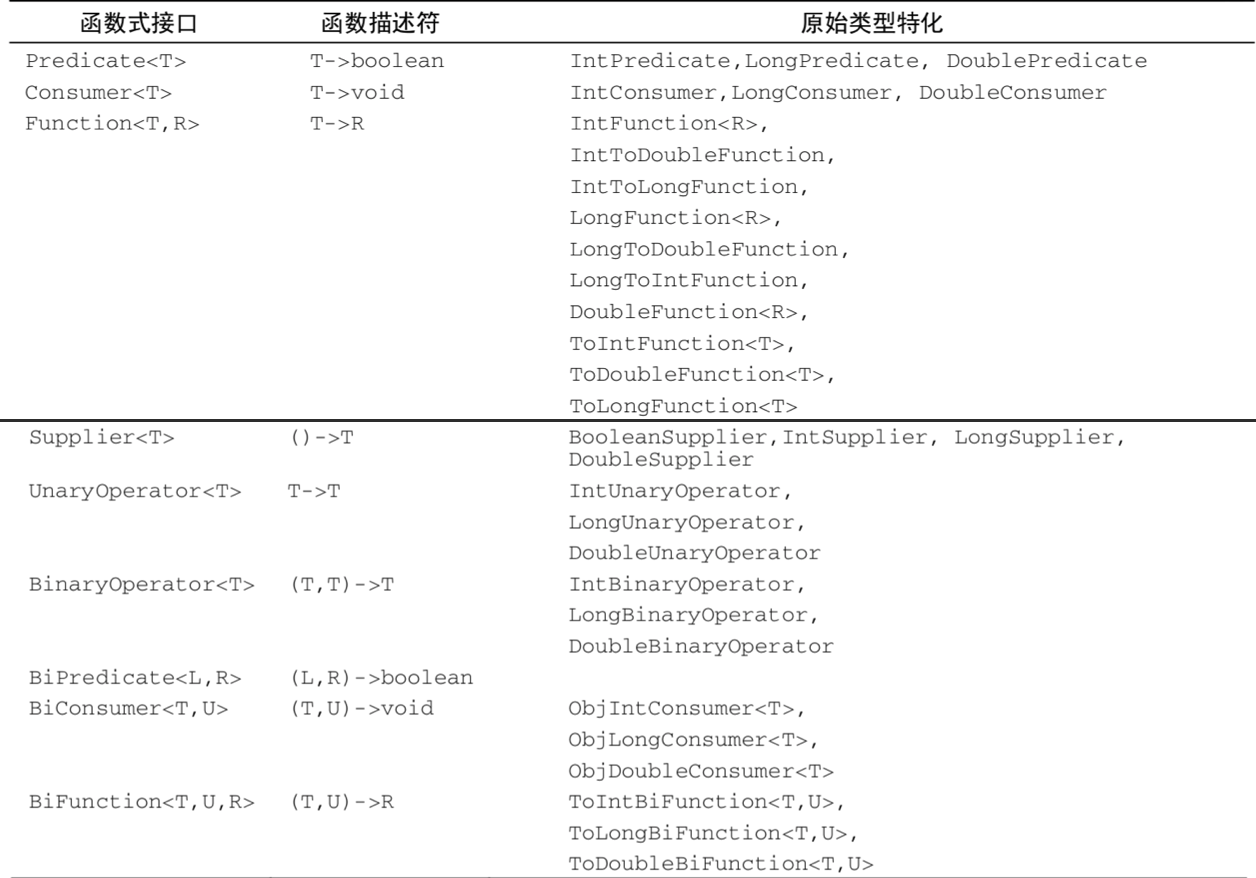
/** * Represents a predicate (boolean-valued function) of one argument. * <p>This is a <a href="package-summary.html">functional interface</a> * whose functional method is {@link #test(Object)}. * @param <T> the type of the input to the predicate * @since 1.8 */ @FunctionalInterface publicinterfacePredicate<T> { /** * Evaluates this predicate on the given argument. * @param t the input argument * @return {@code true} if the input argument matches the predicate, * otherwise {@code false} */ booleantest(T t); }
/** * Represents an operation that accepts a single input argument and returns no * result. Unlike most other functional interfaces, {@code Consumer} is expected * to operate via side-effects. * <p>This is a <a href="package-summary.html">functional interface</a> * whose functional method is {@link #accept(Object)}. * @param <T> the type of the input to the operation * @since 1.8 */ @FunctionalInterface publicinterfaceConsumer<T> { /** * Performs this operation on the given argument. * @param t the input argument */ voidaccept(T t); }
/** * Represents a function that accepts one argument and produces a result. * <p>This is a <a href="package-summary.html">functional interface</a> * whose functional method is {@link #apply(Object)}. * @param <T> the type of the input to the function * @param <R> the type of the result of the function * @since 1.8 */ @FunctionalInterface publicinterfaceFunction<T, R> { /** * Applies this function to the given argument. * @param t the function argument * @return the function result */ R apply(T t); }
andThen方法会返回一个函数,它先对输入应用一个给定函数,再对输出应用另一个函数。 比如, Function<Integer, Integer> f = x -> x + 1; Function<Integer, Integer> g = x -> x * 2; Function<Integer, Integer> h = f.andThen(g); int result = h.apply(1); 数学上会写作g(f(x))或(g o f)(x) 这将返回4
compose方法,先把给定的函数用作compose的参数里面给的那个函 数,然后再把函数本身用于结果。 Function<Integer, Integer> f = x -> x + 1; Function<Integer, Integer> g = x -> x * 2; Function<Integer, Integer> h = f.compose(g); int result = h.apply(1); 数学上会写作f(g(x))或(f o g)(x) 这将返回3
堆内存分配并发解决方案:对分配内存空间的动作进行同步处理,实际上虚拟机采用 CAS 配上失败重试的方式保证更新操作的原子性。本地线程分配缓冲 TLAB (Thread Local Allocation Buffer),把内存分配的动作按照线程划分为在不同的空间之中进行,即每个线程在Java堆中预先分配一小块内存,称为本地线程分配缓冲(TLAB)。哪个线程要分配内存,就在哪个线程的TLAB上分配。只有TLAB用完并分配新的TLAB时,才需要同步锁定。
2.3.2 对象的内存布局
对象头( Header )
对象自身运行时数据 ( Mark Word ),包含:哈希码 / GC分代年龄 / 锁状态标志 / 线程持有的锁 / 偏向线程ID / 偏向时间戳
publicstaticvoidmain(String[] args){ List<OOMObject> list = new ArrayList<>(); while (true) { list.add(new OOMObject()); System.out.println(list.size()); } } }
1 2 3 4 5 6 7 8 9 10 11 12 13
java.lang.OutOfMemoryError: Java heap space Dumping heap to java_pid1439.hprof ... Heap dump file created [28440089 bytes in 0.115 secs] Exception in thread "main" java.lang.OutOfMemoryError: Java heap space at java.util.Arrays.copyOf(Arrays.java:3210) at java.util.Arrays.copyOf(Arrays.java:3181) at java.util.ArrayList.grow(ArrayList.java:265) at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:239) at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:231) at java.util.ArrayList.add(ArrayList.java:462) at OutOfMemory.HeapOOM.main(HeapOOM.java:20)
设置128k,启动会报下面的问题 The stack size specified is too small, Specify at least 160k Error: Could not create the Java Virtual Machine. Error: A fatal exception has occurred. Program will exit.
1 2 3 4 5
修改为161k,实现效果 stack length:7738 Exception in thread "main" java.lang.StackOverflowError at OutOfMemory.JavaVMStackSOF.stackLeak(JavaVMStackSOF.java:22) at OutOfMemory.JavaVMStackSOF.stackLeak(JavaVMStackSOF.java:22)
/** * 运行时常量池导致内存溢出 * VM Args: -XX:PermSize=10m -XX:MaxPermSize=10M * jdk1.6 * * 使用新版本的jdk会输出: * Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=10m; support was removed in 8.0 * Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=10M; support was removed in 8.0 * * @author lujiahao * @date 2018-12-21 17:33 */ publicclassRuntimeConstantPoolOOM{ publicstaticvoidmain(String[] args){ // 使用List保持炸常量池引用,避免Full GC回收常量池行为 List<String> list = new ArrayList<>(); // 10MB的PermSize在Integer范围内足够产生OOM了 int i = 0; while (true) { list.add(String.valueOf(i++).intern()); } } }