《Elasticsearch技术解析与实战》Chapter 2.1 Elasticsearch索引增删改查
1. 创建索引
1 | PUT /lujiahao123 |
1 | PUT /lujiahao123 |
1 | <!-- Spring Boot Elasticsearch 依赖 --> |
1 |
|
1 |
|
1 |
|
1 | (SpringRunner.class) |
1 | <!--elasticsearch--> |
同上
1 |
|
1 | (SpringRunner.class) |
1 | https://github.com/lujiahao0708/LearnSeries/tree/master/LearnElasticSerach |
本文同步发表在公众号,欢迎大家关注!😁
后续笔记欢迎关注获取第一时间更新!
语法格式:
PUT /index/type/id
{
"json数据"
}输入:
PUT /person/chinese/1
{
"id":12345,
"name":"lujiahao",
"age":18
}输出:
{
"_index": "person",
"_type": "chinese",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}es会自动建立index和type,不需要提前创建,而且es默认会对document每个field都建立倒排索引,让其可以被搜索。
格式:
GET /index/type/id输入:
GET /person/chinese/1输出:
{
"_index": "person",
"_type": "chinese",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"id": 12345,
"name": "lujiahao",
"age": 18
}
}格式:
PUT /index/type/id
{
"json数据"
}输入:
PUT /person/chinese/1
{
"name":"lujiahao123"
}输出:
{
"_index": "person",
"_type": "chinese",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}查询:
{
"_index": "person",
"_type": "chinese",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"name": "lujiahao123"
}
}替换方式更新文档时,必须带上所有的field,才能去进行信息的修改;如果缺少field就会丢失部分数据。其原理时替换,因此需要全部字段。不推荐此种方式更新文档。
格式:
POST /index/type/id/_update
{
"doc":{
"json数据"
}
}输入:
POST /person/chinese/1/_update
{
"doc":{
"name":"lujiahao10010"
}
}输出:
{
"_index": "person",
"_type": "chinese",
"_id": "1",
"_version": 4,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}再次查询:
{
"_index": "person",
"_type": "chinese",
"_id": "1",
"_version": 6,
"found": true,
"_source": {
"id": 12345,
"name": "lujiahao10010",
"age": 18
}
}格式:
DELETE /index/type/id/_update
{
"doc":{
"json数据"
}
}输入:
DELETE /person/chinese/1输出:
{
"found": true,
"_index": "person",
"_type": "chinese",
"_id": "1",
"_version": 7,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}再次查询:
{
"_index": "person",
"_type": "chinese",
"_id": "1",
"found": false
}本文所有操作都是在kibana的Dev tools中进行的,相较于Elasticsearch-Heade插件,kibana中更加方便与美观(个人观点),推荐大家使用。
本文同步发表在公众号,欢迎大家关注!😁
后续笔记欢迎关注获取第一时间更新!
1 | https://www.elastic.co/downloads/elasticsearch |
1 | tar -zxvf elasticsearch-6.7.0.tar.gz |
1 | cd elasticsearch-6.7.0 |
1 | curl http://localhost:9200 或者浏览器访问 |
官方文档 : https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html
1 | docker pull docker.elastic.co/elasticsearch/elasticsearch:5.5.1 |
1 | docker run -p 9200:9200 9300:9300 -e "http.host=0.0.0.0" -e “transport.host=0.0.0.0" --name elasticsearch_5.5.0 -d docker.elastic.co/elasticsearch/elasticsearch:5.5.0 |
1 | 进入到容器中 : docker exec -it elasticsearch_5.5.0 /bin/bash |
1 | http://服务器ip:9200 |
本文同步发表在公众号,欢迎大家关注!😁
后续笔记欢迎关注获取第一时间更新!
Elasticsearch是一个机遇Lucene构建的开源、分布式、RESTful接口全文搜索引擎。同时,Elasticsearch还是一个分布式文档数据库,能够扩展至数百个服务器存储以处理PB级数据,通常作为复杂搜索场景的首选利器。
Elasticsearch的优点:
Elasticsearch wiki:https://zh.wikipedia.org/wiki/Elasticsearch
在数据量少的情况下可以当做搜索服务来使用,然而数据库归根结底是做持久化存储。如果数据量大就需要做搜索服务,底层数据还是关系数据库。我司老系统中有一个订单表,数据量已经高达两亿,客服等后台系统通常带有范围或批量条件等查询,这时数据库基本上就无法响应了,报警根本停不下来。因此,用数据库来实现搜索,性能差,可用性不高。
Lucene是一个开源的全文搜索引擎工具包,其目的是为开发者提供一个简单工具包,以快速实现全文检索的功能。
Lucene wiki:https://zh.wikipedia.org/wiki/Lucene
倒排索引中的索引对象是文档或者文档集合中的单词等,用来存储这些单词在一个文档或者一组文档中的存储位置,是对文档或者文档集合的一种最常用的索引机制。搜索引擎的关键步骤就是建立倒排索引,下面介绍Lucene是如何建立倒排索引和相应的生成算法。
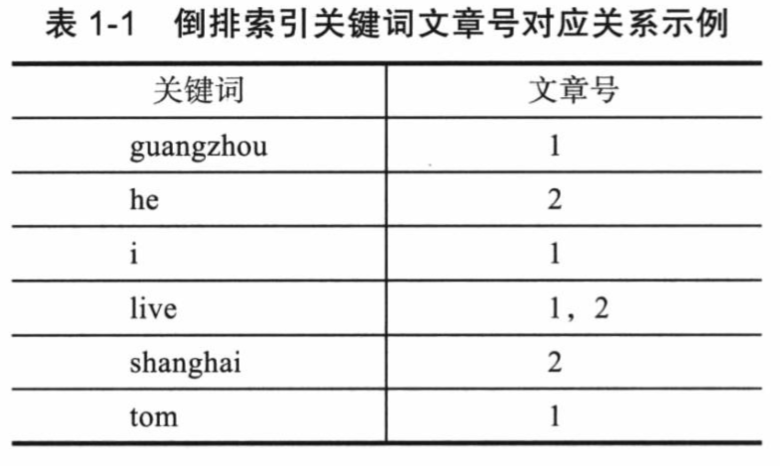
假设有两篇文章:
文章1:Tom lives in Guangzhou, I live in Guangzhou too.
文章2:He once lived in Shanghai.
Lucene是基于关键词索引和查询的,首先要进行关键词提取:
分词:英文单词由空格分隔,较好处理;中文词语由于是连在一起的,需要进行特殊的分词处理(后面会介绍分词器相关知识)。
过滤无概念词语:英文中“in”“once”“too”等词没有实际意义;中文中“的”“是”等也无实际意义,这些无概念词语可以过滤掉。
统一大小写:“he”和“HE”表示的含义一样,所以单词需要统一大小写。
语义还原:通常用户查询“live”时希望能将“lives”和“lived”也查询出来,所以需要将“lives”和“lived”还原成“live”。
过滤标点符号
经过以上过滤,得到如下结果:
文章1关键词:tom live guangzhou i live guangzhou
文章2关键词:he live shanghai
关键词建立完成后,就可以进行倒排索引建立了。过滤后的关系是:“文章号“对”文章中所有关键词“,倒排索引把这个关系倒过来变成:”关键词“对”拥有关键词的所有文章号“。
通常仅知道关键词在哪些文章中出现还不够,还需要知道关键词在文章中出现的次数和位置,通常有两种位置:
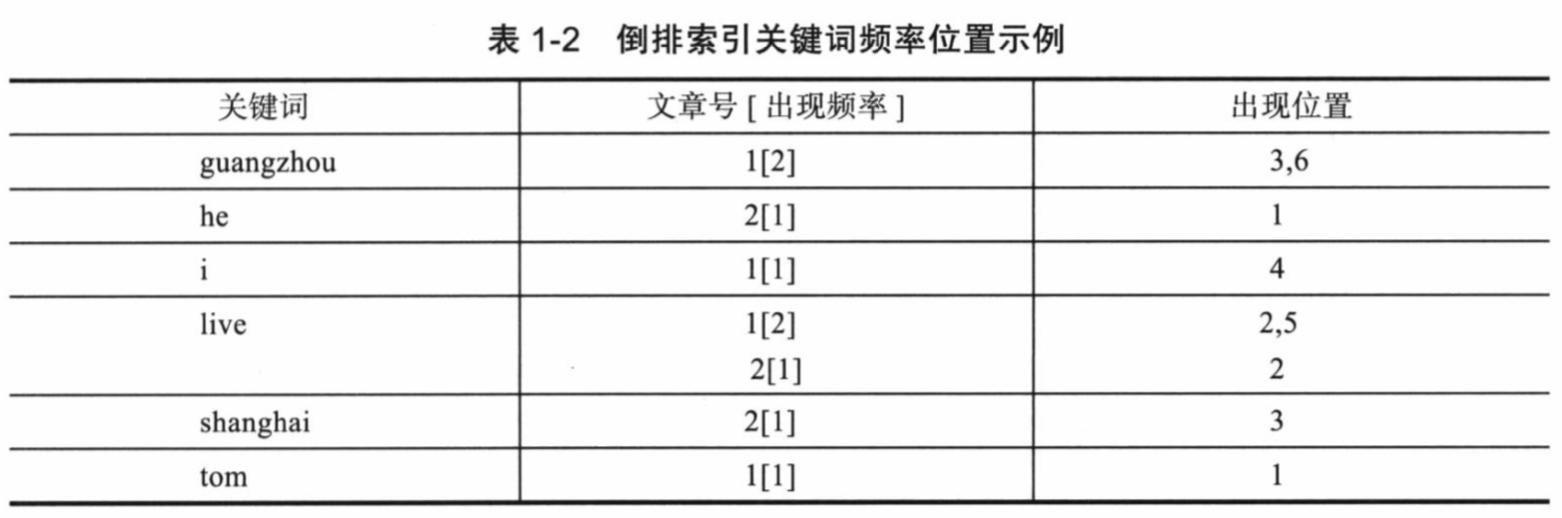
以上就是Lucene索引结构中最核心的部分,关键字是按字符顺序排列的(Lucene没有使用B树结构),因此Lucene可以使用二元搜索算法快速定位关键词。
Lucene将上面三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)、位置文件(positions)保存。其中词典文件不仅保存了每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息。
Lucene中使用了field的概念,用于表达信息所在的位置(如标题中、文章中、url中),在建索引中,该field信息也记录在词典文件中,每个关键词都有一个field信息,因为每个关键字一定属于一个或多个field。
为了减小索引文件的大小,Lucene对索引还是用了压缩技术。
首先,对词典文件中的关键词进行压缩,关键词压缩为<前缀长度,后缀>,例如:当前词为”阿拉伯语“,上一个词为”阿拉伯“,那么”阿拉伯语“压缩为<3,语>。
其次大量用到的是对数字的压缩,数字只保存与上一个值的差值(这样可以减少数字的长度,进而减少保存该数字需要的字节数)。例如当前文章号是16389(不压缩要用3个字节),上一文章号是16382,压缩后保存7(只用一个字节)。
压缩算法推荐阅读:https://www.cnblogs.com/dreamroute/p/8484457.html
查询单词”live“,Lucene先对词典二元查找,找到该词,通过指向频率文件的指针读出所有文章号,然后返回结果。词典通常非常小,可以达到毫秒级返回。而用普通的顺序匹配算法,不建立索引,而是对所有文章的内容进行字符串匹配,过程是很缓慢的,当数据量很大时,耗时更加严重。
Elasticsearch中能够被索引的精确值。foo、Foo、FOO几个单词是不同的索引词。索引词可以通过term查询进行准确的搜索。
文本会被拆分成一个个索引词存储在索引库中,为后续搜索提供支持。
分析是将文本转换为索引词的过程,其结果依赖于分词器。
集群由一个或多个节点组成,对外提供服务。Elasticsearch节点如果有相同的集群名称会自动加入到同一个集群,因此如果你拥有多个独立集群,每个集群都要设置不同的名称。
节点是一个逻辑上独立的服务,是集群的一部分,可以存储数据,并参与集群的索引和搜索功能。
文档存储时是通过散列值进行计算,最终选择存储在主分片中,这个值默认是由文档的ID生成。
分片是单个Lucene实例,是Elasticsearch管理的比较底层的功能。当索引占用空间很大超过一个节点的物理存储,Elasticsearch将索引切分成多个分片,分散在不同的物理节点上,以解决单物理节点存储空间有限的问题。
每个文档都存储在一个分片中,存储文档时系统会首先存储在主分片中,然后复制到不同的副本中。默认情况下一个索引拥有5个主分片,分片一旦建立,主分片数量就无法修改。
每个主分片有零个或多个副本,是主分片的复制,其主要目的是:
主分片的数据会复制到副本分片中,这样避免了单点问题,当某个节点发生故障,复制可以对故障进行转移,保证系统的高可用。
索引是具有相同结构的文档合集。
一个索引可以定义一个或多个类型,类型是索引的逻辑分区。
文档是存储在Elasticsearch中的一个JSON格式的字符串,就像关系数据库中表的一行记录。
映射像关系数据库中的表结构,每个索引都有一个映射,它定义了索引中的每一个字段类型。映射可以事先被定义,也可以在第一次存储文档时被自动识别。
文档中包含零个或多个字段,字段可以是一个简单的值,也可以是一个数组或对象的嵌套结构。字段类似于关系数据库中表的列,每个字段都对应一个字段类型。
默认情况下源文档将被存储在_source字段中,查询时返回该字段。
ID是文件的唯一标识,如果未指定,系统会自动生成一个ID,文档的index/type/id必须是唯一的。
| Elasticsearch | 数据库 |
|---|---|
| Document | row 行 |
| Type | table 表 |
| Index | database 库 |
本文同步发表在公众号,欢迎大家关注!😁
后续笔记欢迎关注获取第一时间更新!