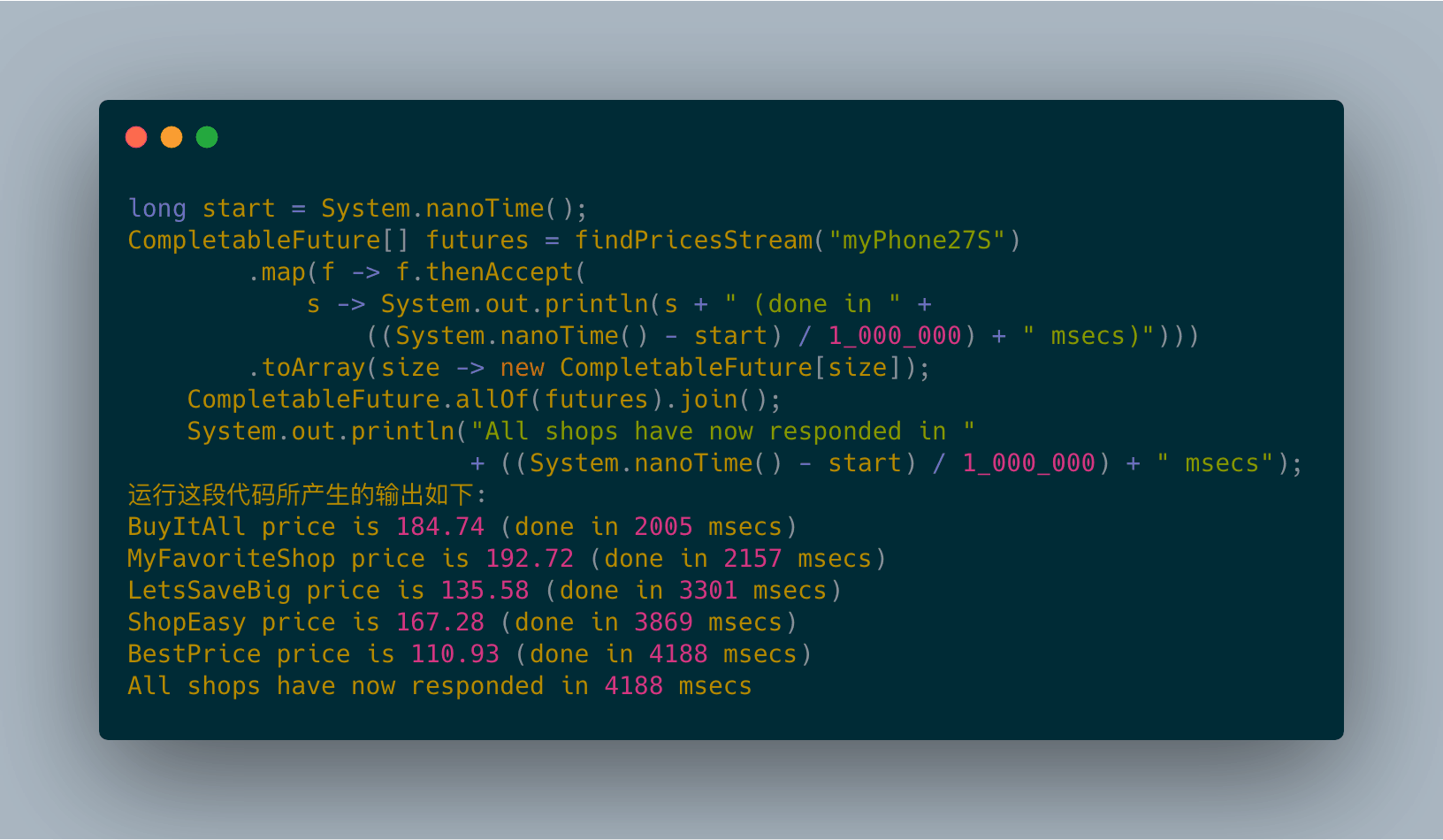
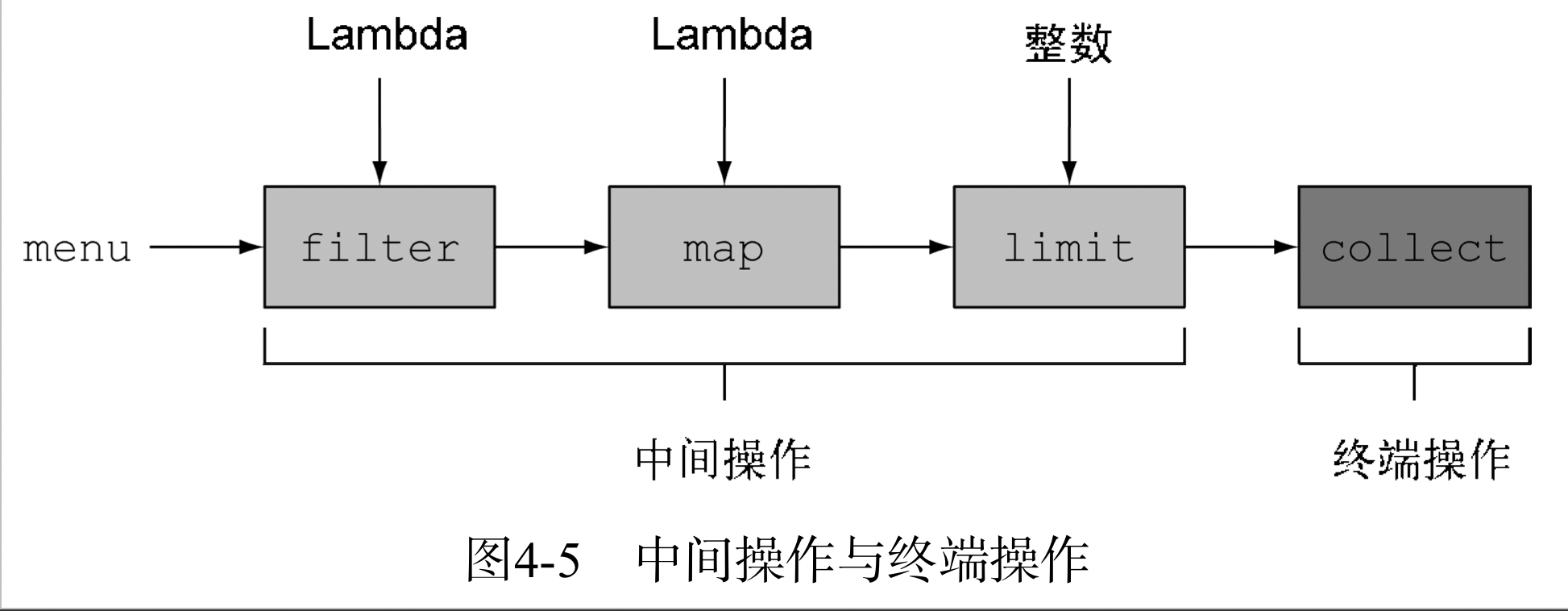
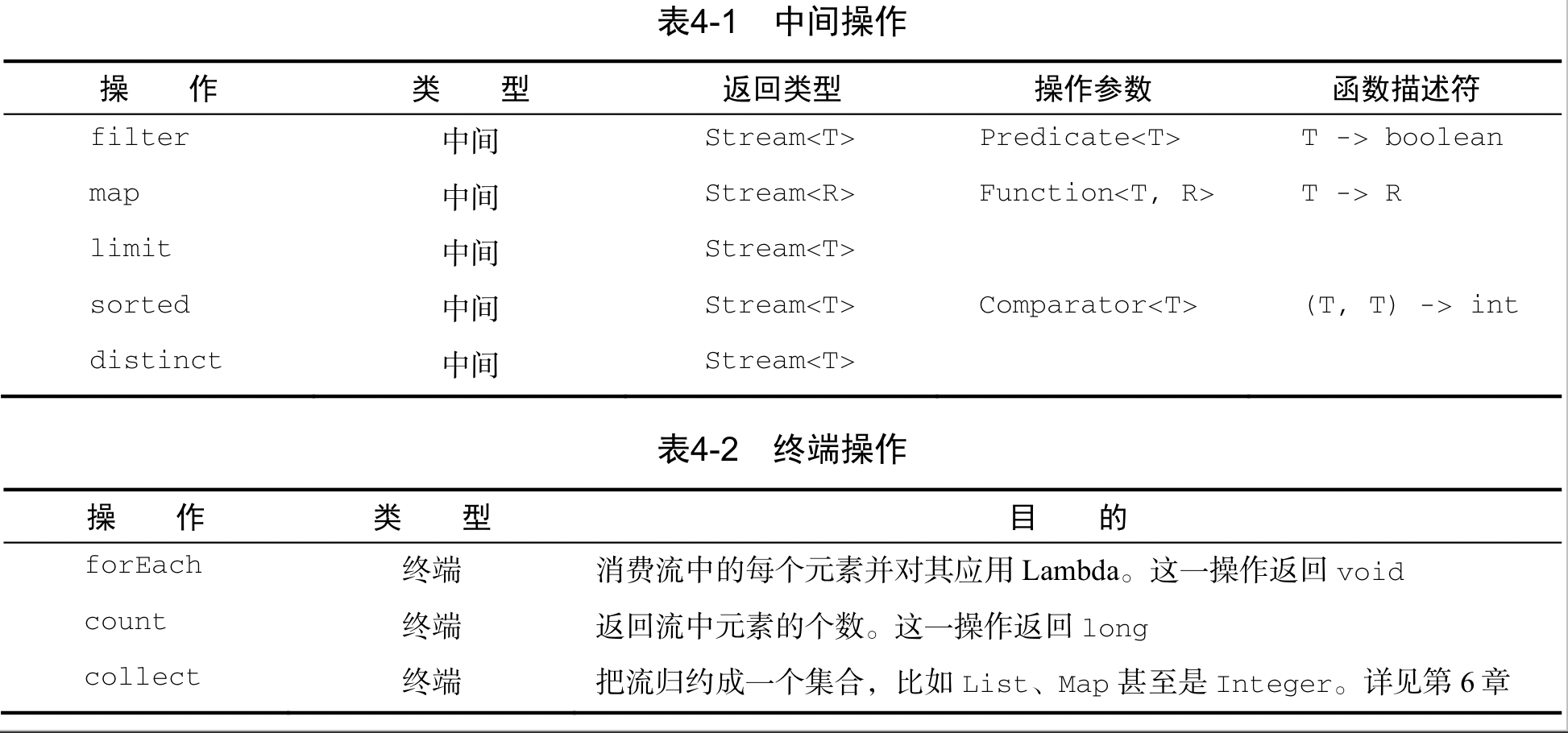
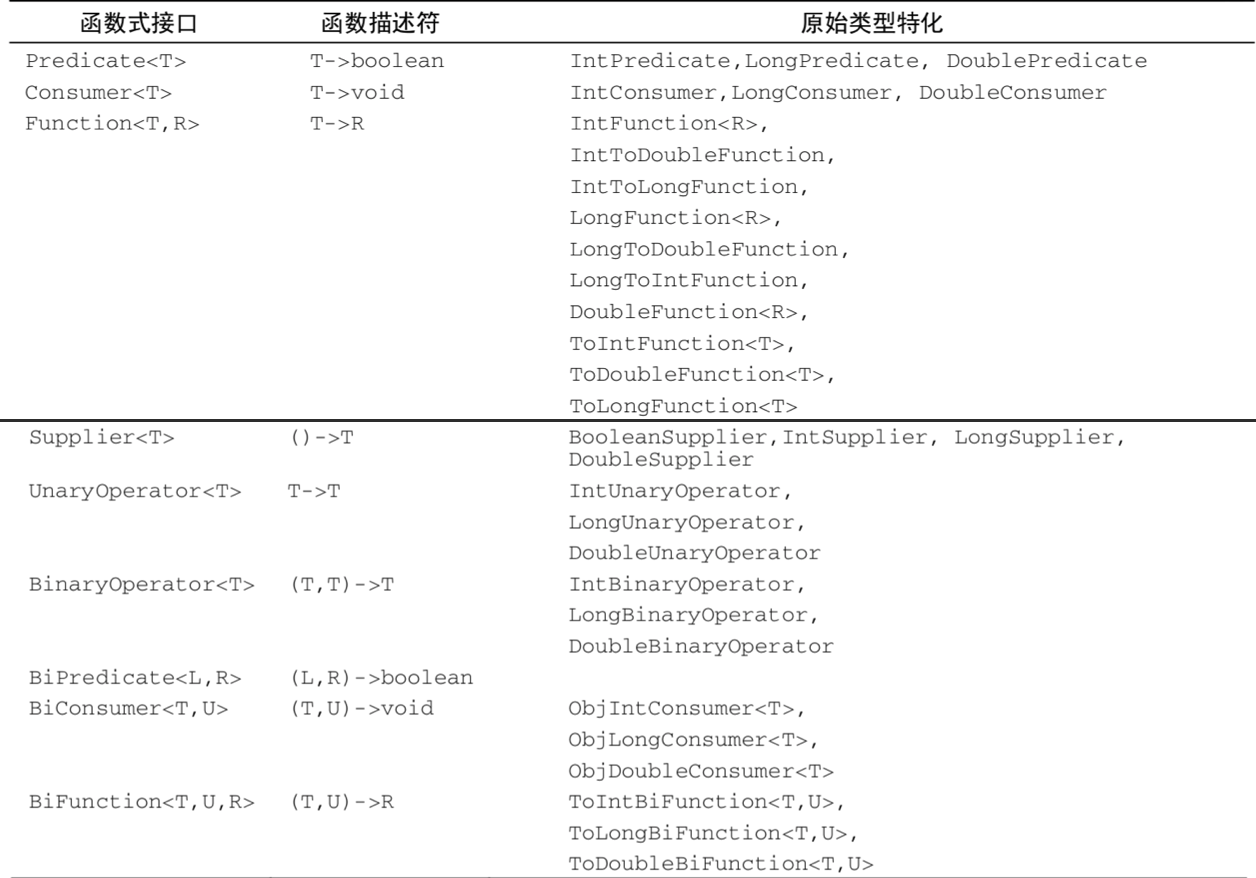
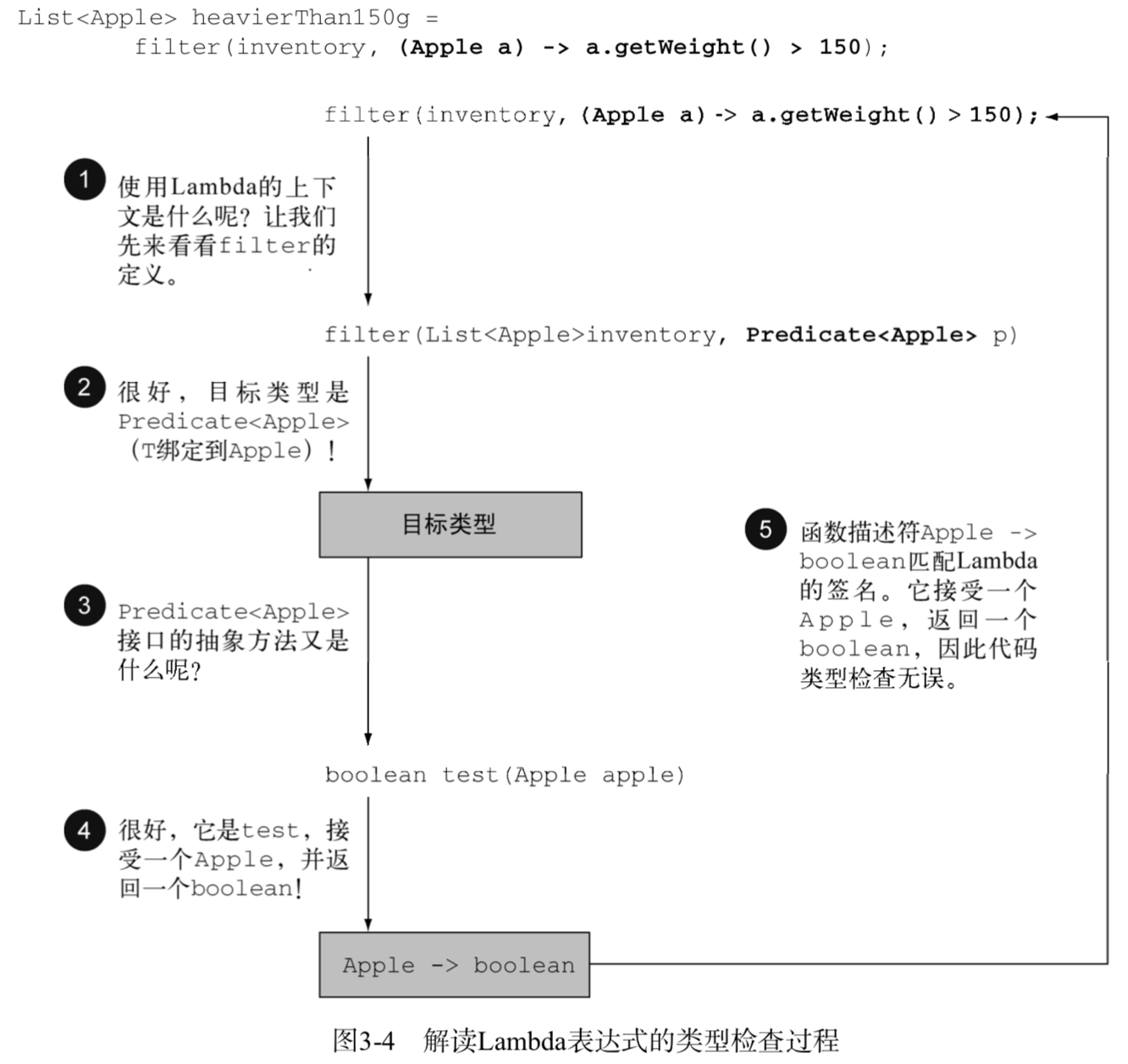
《Java 8 in Action》Chapter 12:新的日期和时间API
- 在Java 1.0中,对日期和时间的支持只能依赖java.util.Date类。同时这个类还有两个很大的缺点:年份的起始选择是1900年,月份的起始从0开始。
- 在Java 1.1中,Date类中的很多方法被废弃,取而代之的是java.util.Calendar类。然而Calendar类也有类似的问题和设计缺陷,导致使用这些方法写出的代码非常容易出错。
DateFormat方法也有它自己的问题。比如,它不是线程安全的。这意味着两个线程如果尝试使用同一个formatter解析日期,你可能会得到无法预期的结果。
1. 使用LocalDate 和LocalTime
1.1 LocalDate
Java 8提供新的日期和时间API,LocalDate类实例是一个不可变对象,只提供简单的日期并且不含当天时间信息。此外也不附带任何与时区相关的信息。
通过静态工厂方法of创建一个LocalDate实例。LocalDate实例提供了多种方法来读取常用的值,比如年份、月份、星期几等,如下所示。
1 | LocalDate localDate = LocalDate.of(2014, 3, 18); |
Java 8日期-时间类都提供了类似的工厂方法。通过传递TemporalField参数给get方法拿到同样的信息。TemporalField接口定义了如何访问temporal对象某个字段的值。ChronoField枚举实现TemporalField接口,可以使用get方法得到枚举元素的值。
1 | int year = localDate.get(ChronoField.YEAR); |
1.2 LocalTime
使用LocalTime类表示时间,可以使用of重载的两个工厂方法创建LocalTime的实例。
- 第一个重载函数接收小时和分钟
- 第二个重载函数同时还接收秒。
LocalTime类也提供了一些get方法访问这些变量的值,如下所示。
1 | LocalTime localTime = LocalTime.of(13, 45, 20); |
LocalDate和LocalTime都可以通过解析代表它们的字符串创建。使用静态方法parse可以实现:
1 | LocalDate date = LocalDate.parse("2019-03-27"); |
可以向parse方法传递一个DateTimeFormatter。该类的实例定义了如何格式化一个日期或者时间对象。用来替换老版java.util.DateFormat。
如果传递的字符串参数无法被解析为合法的LocalDate或LocalTime对象,这两个parse方法都会抛出一个继承自RuntimeException的DateTimeParseException异常。
2. 合并日期和时间
复合类LocalDateTime,是LocalDate和LocalTime的合体。它同时表示了日期和时间,不带有时区信息。可以直接创建,也可以通过合并日期和时间对象构造。
1 | LocalTime time = LocalTime.of(21, 31, 50); |
创建LocalDateTime对象
- 直接创建
- 通过atTime方法向LocalDate传递一个时间对象
- 通过atDate方法向LocalTime传递一个时间对象
也可以使用toLocalDate或者toLocalTime方法,从LocalDateTime中提取LocalDate或者LocalTime组件:
1 | LocalDate date1 = dt1.toLocalDate(); |
3. 机器的日期和时间格式
从计算机的角度来看,”2019年03月27日11:20:03”这样的方式是不容易理解的,计算机更加容易理解建模时间最自然的格式是表示一个持续时间段上某个点的单一大整型数。新的java.time.Instant类对时间建模的方式,基本上它是以Unix元年时间(传统的设定为UTC时区1970年1月1日午夜时分)开始所经历的秒数进行计算。
3.1 创建Instant
- 静态工厂方法ofEpochSecond传递一个代表秒数的值创建一个该类的实例。
- 静态工厂方法ofEpochSecond还有一个增强的重载版本,它接收第二个以纳秒为单位的参数值,对传入作为秒数的参数进行调整。重载的版本会调整纳秒参数,确保保存的纳秒分片在0到999 999999之间。
1 | Instant.ofEpochSecond(3); |
3.2 工厂方法now
Instant类也支持静态工厂方法now,它能够获取当前时刻的时间戳。
1 | Instant now = Instant.now(); |
Instant的设计初衷是为了便于机器使用,它包含的是由秒及纳秒所构成的数字。因此Instant无法处理那些我们非常容易理解的时间单位。
1 | int day = Instant.now().get(ChronoField.DAY_OF_MONTH); |
4. Duration和Period
4.1 Duration
所有类都实现了Temporal接口,该接口定义如何读取和操纵为时间建模的对象的值。如果需要创建两个Temporal对象之间的duration,就需要Duration类的静态工厂方法between。
可以创建两个LocalTimes对象、两个LocalDateTimes对象,或者两个Instant对象之间的duration:
1 | LocalTime time1 = LocalTime.of(21, 50, 10); |
LocalDateTime是为了便于人阅读使用,Instant是为了便于机器处理,所以不能将二者混用。如果在这两类对象之间创建duration,会触发一个DateTimeException异常。
此外,由于Duration类主要用于以秒和纳秒衡量时间的长短,你不能仅向between方法传递一个LocalDate对象做参数。
4.2 Period
使用Period类以年、月或者日的方式对多个时间单位建模。使用该类的工厂方法between,可以使用得到两个LocalDate之间的时长。
1 | Period period = Period.between(LocalDate.of(2019, 03, 7), LocalDate.of(2019, 03, 17)); |
Duration和Period类都提供了很多非常方便的工厂类,直接创建对应的实例。
1 | Duration threeMinutes = Duration.ofMinutes(3); |
截至目前,我们介绍的这些日期-时间对象都是不可修改的,这是为了更好地支持函数式编程,确保线程安全,保持领域模式一致性而做出的重大设计决定。
当然,新的日期和时间API也提供了一些便利的方法来创建这些对象的可变版本。比如,你可能希望在已有的LocalDate实例上增加3天。除此之外,我们还会介绍如何依据指定的模式,
比如dd/MM/yyyy,创建日期-时间格式器,以及如何使用这种格式器解析和输出日期。
5. 操纵、解析和格式化日期
如果已经有一个LocalDate对象,想要创建它的一个修改版,最直接也最简单的方法是使用withAttribute方法。withAttribute方法会创建对象的一个副本,并按照需要修改它的属性。
1 | // 这段代码中所有的方法都返回一个修改了属性的对象。它们都不会修改原来的对象! |
它们都声明于Temporal接口,所有的日期和时间API类都实现这两个方法,它们定义了单点的时间,比如LocalDate、LocalTime、LocalDateTime以及Instant。更确切地说,使用get和with方法,我们可以将Temporal对象值的读取和修改区分开。如果Temporal对象不支持请求访问的字段,它会抛出一个UnsupportedTemporalTypeException异常,比如试图访问Instant对象的ChronoField.MONTH_OF_YEAR字段,或者LocalDate对象的ChronoField.NANO_OF_SECOND字段时都会抛出这样的异常。
1 | // 以声明的方式操纵LocalDate对象,可以加上或者减去一段时间 |
与我们刚才介绍的get和with方法类似最后一行使用的plus方法也是通用方法,它和minus方法都声明于Temporal接口中。通过这些方法,对TemporalUnit对象加上或者减去一个数字,我们能非常方便地将Temporal对象前溯或者回滚至某个时间段,通过ChronoUnit枚举我们可以非常方便地实现TemporalUnit接口。
6. 使用TemporalAdjuster
有时需要进行一些更加复杂的操作,比如,将日期调整到下个周日、下个工作日,或者是本月的最后一天。可以使用重载版本的with方法,向其传递一个提供了更多定制化选择的TemporalAdjuster对象,更加灵活地处理日期。
1 | // 对于最常见的用例,日期和时间API已经提供了大量预定义的TemporalAdjuster。可以通过TemporalAdjuster类的静态工厂方法访问。 |
使用TemporalAdjuster可以进行更加复杂的日期操作,方法的名称很直观。如果没有找到符合预期的预定义的TemporalAdjuster,可以创建自定义的TemporalAdjuster。TemporalAdjuster接口只声明一个方法(即函数式接口)。实现该接口需要定义如何将一个Temporal对象转换为另一个Temporal对象,可以把它看成一个UnaryOperator
1 |
|
7. 打印输出及解析日期-时间对象
新的java.time.format包就是特别为格式化以及解析日期-时间对象而设计的。其中最重要的类是DateTimeFormatter。创建格式器最简单的方法是通过它的静态工厂方法以及常量。所有的DateTimeFormatter实例都能用于以一定的格式创建代表特定日期或时间的字符串。
1 | LocalDate date = LocalDate.of(2013, 10, 11); |
通过解析代表日期或时间的字符串重新创建该日期对象,也可以使用工厂方法parse重新创建。
1 | LocalDate date2 = LocalDate.parse("20141007", DateTimeFormatter.BASIC_ISO_DATE); |
DateTimeFormatter实例是线程安全的,老的java.util.DateFormat线程不安全。单例模式创建格式器实例,在多个线程间共享实例是没有问题的。也可以通过ofPattern静态工厂方法,按照某个特定的模式创建格式器。
1 | DateTimeFormatter formatter = DateTimeFormatter.ofPattern("dd/MM/yyyy"); |
ofPattern方法也提供了一个重载的版本,可以传入Locale创建格式器。
1 | DateTimeFormatter italianFormatter = DateTimeFormatter.ofPattern("d. MMMM yyyy", Locale.ITALIAN); |
DateTimeFormatterBuilder类还提供了更复杂的格式器,以提供更加细粒度的控制。同时也提供非常强大的解析功能,比如区分大小写的解析、柔性解析、填充,以及在格式器中指定可选节等等。
通过DateTimeFormatterBuilder自定义格式器
1 | DateTimeFormatter italianFormatter = new DateTimeFormatterBuilder() |
8. 处理不同的时区和历法
新版日期和时间API新增加的重要功能是时区的处理。新的java.time.ZoneId类替代老版java.util.TimeZone。跟其他日期和时间类一样,ZoneId类也是无法修改的。是按照一定的规则将区域划分成的标准时间相同的区间。在ZoneRules这个类中包含了40个时区实例,可以通过调用ZoneId的getRules()得到指定时区的规则,每个特定的ZoneId对象都由一个地区ID标识。
1 | ZoneId shanghaiZone = ZoneId.of("Asia/Shanghai"); |
Java 8的新方法toZoneId将一个老的时区对象转换为ZoneId。地区ID都为“{区域}/{城市}”的格式,地区集合的设定都由英特网编号分配机构(IANA)的时区数据库提供。
1 | ZoneId zoneId = TimeZone.getDefault().toZoneId(); |
ZoneId对象可以与LocalDate、LocalDateTime或者是Instant对象整合构造为成ZonedDateTime实例,它代表了相对于指定时区的时间点。
1 | LocalDate date = LocalDate.of(2019, 03, 27); |
另一种比较通用的表达时区的方式是利用当前时区和UTC/格林尼治的固定偏差。使用ZoneId的一个子类ZoneOffset,表示的是当前时间和伦敦格林尼治子午线时间的差异:
1 | ZoneOffset newYorkOffset = ZoneOffset.of("-05:00"); |
9. 总结
- Java 8之前老版的java.util.Date类以及其他用于建模日期时间的类有很多不一致及设计上的缺陷,包括易变性以及糟糕的偏移值、默认值和命名。
- 新版的日期和时间API中,日期-时间对象是不可变的。
- 新的API提供了两种不同的时间表示方式,有效地区分了运行时人和机器的不同需求。
- 你可以用绝对或者相对的方式操纵日期和时间,操作的结果总是返回一个新的实例,老的日期时间对象不会发生变化。
- TemporalAdjuster让你能够用更精细的方式操纵日期,不再局限于一次只能改变它的一个值,并且你还可按照需求定义自己的日期转换器。
- 你现在可以按照特定的格式需求,定义自己的格式器,打印输出或者解析日期时间对象。这些格式器可以通过模板创建,也可以自己编程创建,并且它们都是线程安全的。
- 你可以用相对于某个地区/位置的方式,或者以与UTC/格林尼治时间的绝对偏差的方式表示时区,并将其应用到日期时间对象上,对其进行本地化。
资源获取
- 公众号回复 : Java8 即可获取《Java 8 in Action》中英文版!
Tips
- 欢迎收藏和转发,感谢你的支持!(๑•̀ㅂ•́)و✧
- 欢迎关注我:后端小哥,专注后端开发,希望和你一起进步!


.png)